skimage.graph#
基於圖形的操作,例如最短路徑。
這包括建立影像中像素的鄰接圖、尋找影像中的中心像素、尋找像素間(最小成本)路徑、合併和切割圖形等等。
尋找具有最高接近中心性的像素。 |
|
對區域鄰接圖執行正規化圖形切割。 |
|
合併權重小於閾值的區域。 |
|
對 RAG 執行階層式合併。 |
|
在影像中建立像素的鄰接圖。 |
|
基於區域邊界計算 RAG。 |
|
使用平均顏色計算區域鄰接圖。 |
|
如何使用 MCP 和 MCP_Geometric 類別的簡單範例。 |
|
尋找通過 n 維陣列從一側到另一側的最短路徑。 |
|
在影像上顯示區域鄰接圖。 |
|
用於尋找通過給定 n 維成本陣列的最小成本路徑的類別。 |
|
使用距離加權的最小成本函數連接源點。 |
|
尋找通過 N 維成本陣列的最小成本路徑。 |
|
尋找通過 n 維成本陣列的距離加權最小成本路徑。 |
|
影像的區域鄰接圖 (RAG),是 |
- skimage.graph.central_pixel(graph, nodes=None, shape=None, partition_size=100)[原始碼]#
尋找具有最高接近中心性的像素。
接近中心性是節點到每個其他節點的最短距離總和的倒數。
- 參數:
- graphscipy.sparse.csr_array 或 scipy.sparse.csr_matrix
圖形的稀疏表示。
- nodes整數陣列
影像中圖形中每個節點的扁平索引。如果未提供,則傳回值將是輸入圖形中的索引。
- shape整數元組
嵌入節點的影像形狀。如果提供,則傳回的座標是與輸入形狀相同維度的 NumPy 多重索引。否則,傳回的座標是
nodes中提供的扁平索引。- partition_size整數
此函數計算圖形中每對節點之間的最短路徑距離。這可能會產生非常大的 (N*N) 矩陣。作為簡單的效能調整,距離值以
partition_size的批次計算,導致記憶體需求僅為 partition_size*N。
- 傳回:
- position整數或整數元組
如果給定形狀,則為影像中中心像素的座標。否則,為該像素的扁平索引。
- distances浮點數陣列
從每個節點到每個其他可到達節點的距離總和。
- skimage.graph.cut_normalized(labels, rag, thresh=0.001, num_cuts=10, in_place=True, max_edge=1.0, *, rng=None)[原始碼]#
對區域鄰接圖執行正規化圖形切割。
給定影像的標籤及其相似性 RAG,在其上遞迴執行雙向正規化切割。無法進一步切割的子圖中的所有節點都會在輸出中被指派唯一的標籤。
- 參數:
- labelsndarray
標籤陣列。
- ragRAG
區域鄰接圖。
- thresh浮點數
閾值。如果 N 切割的值超過
thresh,則子圖將不會進一步細分。- num_cuts整數
在確定最佳切割之前要執行的 N 切割次數。
- in_place布林值
如果設定,則就地修改
rag。對於每個節點n,此函數將設定一個新的屬性rag.nodes[n]['ncut label']。- max_edge浮點數,選用
RAG 中邊的最大可能值。這對應於相同區域之間的邊。這用於將自身邊放入 RAG 中。
- rng{
numpy.random.Generator、整數},選用 虛擬隨機數字產生器。預設情況下,會使用 PCG64 產生器(請參閱
numpy.random.default_rng())。如果rng是整數,則會用它來植入產生器。rng用於決定scipy.sparse.linalg.eigsh的起點。
- 傳回:
- outndarray
新的標記陣列。
參考文獻
[1]Shi, J.; Malik, J., “Normalized cuts and image segmentation”, Pattern Analysis and Machine Intelligence, IEEE Transactions on, vol. 22, no. 8, pp. 888-905, August 2000.
範例
>>> from skimage import data, segmentation, graph >>> img = data.astronaut() >>> labels = segmentation.slic(img) >>> rag = graph.rag_mean_color(img, labels, mode='similarity') >>> new_labels = graph.cut_normalized(labels, rag)

- skimage.graph.cut_threshold(labels, rag, thresh, in_place=True)[原始碼]#
合併權重小於閾值的區域。
給定影像的標籤及其 RAG,透過合併節點之間權重小於給定閾值的區域,輸出新的標籤。
- 參數:
- labelsndarray
標籤陣列。
- ragRAG
區域鄰接圖。
- thresh浮點數
閾值。以較小權重邊連接的區域會合併。
- in_place布林值
如果設定,則就地修改
rag。此函數將移除權重小於thresh的邊。如果設定為False,則此函數會先複製rag再繼續。
- 傳回:
- outndarray
新的標記陣列。
參考文獻
[1]Alain Tremeau 和 Philippe Colantoni “Regions Adjacency Graph Applied To Color Image Segmentation” DOI:10.1109/83.841950
範例
>>> from skimage import data, segmentation, graph >>> img = data.astronaut() >>> labels = segmentation.slic(img) >>> rag = graph.rag_mean_color(img, labels) >>> new_labels = graph.cut_threshold(labels, rag, 10)

- skimage.graph.merge_hierarchical(labels, rag, thresh, rag_copy, in_place_merge, merge_func, weight_func)[原始碼]#
對 RAG 執行階層式合併。
貪婪地合併最相似的一對節點,直到沒有小於
thresh的邊為止。- 參數:
- labelsndarray
標籤陣列。
- ragRAG
區域鄰接圖。
- thresh浮點數
權重小於
thresh的邊所連接的區域會被合併。- rag_copybool
若設定,則會在修改前複製 RAG。
- in_place_mergebool
若設定,則節點會原地合併。否則,每次合併都會建立一個新節點。
- merge_funccallable
此函數會在合併兩個節點之前被呼叫。對於 RAG
graph,在合併src和dst時,會以merge_func(graph, src, dst)的形式呼叫。- weight_funccallable
計算與合併節點相鄰之節點的新權重的函數。此函數會直接作為
merge_nodes的weight_func引數提供。
- 傳回:
- outndarray
新的標記陣列。
- skimage.graph.pixel_graph(image, *, mask=None, edge_function=None, connectivity=1, spacing=None, sparse_type='matrix')[原始碼]#
在影像中建立像素的鄰接圖。
遮罩為 True 的像素是回傳圖形中的節點,並且根據連通性參數透過邊連接到其相鄰節點。預設情況下,當提供遮罩時,或當影像本身是遮罩時,邊的值是像素之間的歐幾里得距離。
但是,如果提供沒有遮罩的整數或浮點數值影像,則邊的值是相鄰像素之間的強度絕對差異,並根據歐幾里得距離加權。
- 參數:
- image陣列
輸入影像。如果影像類型為布林值,則也會用作遮罩。
- mask布林值陣列
要使用的像素。如果為 None,則會使用整個影像的圖形。
- edge_function可呼叫物件
一個函數,它接受像素值陣列、相鄰像素值陣列以及距離陣列,並傳回邊的值。如果未提供函數,則邊的值只是距離。
- connectivity整數
像素鄰域的平方連通性:考慮像素為相鄰像素所允許的正交步驟數。有關詳細資訊,請參閱
scipy.ndimage.generate_binary_structure。- spacing浮點數元組
沿每個軸的像素間距。
- sparse_type{“matrix”, “array”}, 選用
graph的回傳類型,可以是scipy.sparse.csr_array或scipy.sparse.csr_matrix(預設)。
- 傳回:
- graphscipy.sparse.csr_matrix 或 scipy.sparse.csr_array
一個稀疏鄰接矩陣,其中條目 (i, j) 如果節點 i 和 j 相鄰則為 1,否則為 0。根據
sparse_type,這可以作為scipy.sparse.csr_array回傳。- nodes整數陣列
圖形的節點。這些節點對應於遮罩中非零像素的展平索引。
- skimage.graph.rag_boundary(labels, edge_map, connectivity=2)[原始碼]#
基於區域邊界計算 RAG。
給定影像的初始分割及其邊緣圖,此方法會建構對應的區域鄰接圖 (RAG)。RAG 中的每個節點都代表
labels中具有相同標籤的影像內的一組像素。兩個相鄰區域之間的權重是沿著它們的邊界在edge_map中的平均值。- labelsndarray
已標記的影像。
- edge_mapndarray
此陣列的形狀應與
labels相同。對於 2 個相鄰區域之間的邊界上的所有像素,edge_map中對應像素的平均值是它們之間的邊緣權重。- connectivityint, 選用
與彼此的平方距離小於
connectivity的像素會被視為相鄰。它的範圍可以從 1 到labels.ndim。它的行為與scipy.ndimage.generate_binary_structure中的connectivity參數相同。
範例
>>> from skimage import data, segmentation, filters, color, graph >>> img = data.chelsea() >>> labels = segmentation.slic(img) >>> edge_map = filters.sobel(color.rgb2gray(img)) >>> rag = graph.rag_boundary(labels, edge_map)

- skimage.graph.rag_mean_color(image, labels, connectivity=2, mode='distance', sigma=255.0)[原始碼]#
使用平均顏色計算區域鄰接圖。
給定影像及其初始分割,此方法會建構對應的區域鄰接圖 (RAG)。RAG 中的每個節點都代表
image中具有labels中相同標籤的一組像素。兩個相鄰區域之間的權重表示兩個區域的相似或相異程度,具體取決於mode參數。- 參數:
- imagendarray,形狀 (M, N[, …, P], 3)
輸入影像。
- labelsndarray,形狀 (M, N[, …, P])
已標記的影像。此影像的維度應比
image少一維。如果image的維度為(M, N, 3),則labels的維度應為(M, N)。- connectivityint, 選用
與彼此的平方距離小於
connectivity的像素會被視為相鄰。它的範圍可以從 1 到labels.ndim。它的行為與scipy.ndimage.generate_binary_structure中的connectivity參數相同。- mode{‘distance’, ‘similarity’}, 選用
指派邊緣權重的策略。
‘distance’:兩個相鄰區域之間的權重為 \(|c_1 - c_2|\),其中 \(c_1\) 和 \(c_2\) 是兩個區域的平均顏色。它代表其平均顏色中的歐幾里得距離。
‘similarity’:兩個相鄰之間的權重為 \(e^{-d^2/sigma}\),其中 \(d=|c_1 - c_2|\),其中 \(c_1\) 和 \(c_2\) 是兩個區域的平均顏色。它表示兩個區域的相似程度。
- sigmafloat, 選用
當
mode為 “similarity” 時用於計算。它控制兩個顏色彼此之間應有多接近,其對應的邊緣權重才顯著。很大的sigma值可能會使任何兩種顏色都表現得好像它們相似。
- 傳回:
- outRAG
區域鄰接圖。
參考文獻
[1]Alain Tremeau 和 Philippe Colantoni “Regions Adjacency Graph Applied To Color Image Segmentation” DOI:10.1109/83.841950
範例
>>> from skimage import data, segmentation, graph >>> img = data.astronaut() >>> labels = segmentation.slic(img) >>> rag = graph.rag_mean_color(img, labels)
- skimage.graph.route_through_array(array, start, end, fully_connected=True, geometric=True)[原始碼]#
如何使用 MCP 和 MCP_Geometric 類別的簡單範例。
關於路徑搜尋演算法的說明,請參閱 MCP 和 MCP_Geometric 類別的文件。
- 參數:
- 傳回:
- pathlist
定義從
start到end路徑的 n 維索引元組列表。- costfloat
路徑的成本。若
geometric為 False,則路徑的成本是沿路徑的array值的總和。若geometric為 True,則會進行更精細的計算(請參閱 MCP_Geometric 類別的文件)。
另請參閱
範例
>>> import numpy as np >>> from skimage.graph import route_through_array >>> >>> image = np.array([[1, 3], [10, 12]]) >>> image array([[ 1, 3], [10, 12]]) >>> # Forbid diagonal steps >>> route_through_array(image, [0, 0], [1, 1], fully_connected=False) ([(0, 0), (0, 1), (1, 1)], 9.5) >>> # Now allow diagonal steps: the path goes directly from start to end >>> route_through_array(image, [0, 0], [1, 1]) ([(0, 0), (1, 1)], 9.19238815542512) >>> # Cost is the sum of array values along the path (16 = 1 + 3 + 12) >>> route_through_array(image, [0, 0], [1, 1], fully_connected=False, ... geometric=False) ([(0, 0), (0, 1), (1, 1)], 16.0) >>> # Larger array where we display the path that is selected >>> image = np.arange((36)).reshape((6, 6)) >>> image array([[ 0, 1, 2, 3, 4, 5], [ 6, 7, 8, 9, 10, 11], [12, 13, 14, 15, 16, 17], [18, 19, 20, 21, 22, 23], [24, 25, 26, 27, 28, 29], [30, 31, 32, 33, 34, 35]]) >>> # Find the path with lowest cost >>> indices, weight = route_through_array(image, (0, 0), (5, 5)) >>> indices = np.stack(indices, axis=-1) >>> path = np.zeros_like(image) >>> path[indices[0], indices[1]] = 1 >>> path array([[1, 1, 1, 1, 1, 0], [0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 1]])
- skimage.graph.shortest_path(arr, reach=1, axis=-1, output_indexlist=False)[原始碼]#
尋找通過 n 維陣列從一側到另一側的最短路徑。
- 參數:
- arrfloat64 的 ndarray
- reachint,可選
預設情況下(
reach = 1),最短路徑每往前移動一步,只能向上或向下移動一行(即,路徑梯度限制為 1)。reach定義了在每個步驟中沿每個非軸維度可以跳過的元素數量。- axisint,可選
路徑必須始終向前移動的軸(預設值為 -1)
- output_indexlistbool,可選
請參閱傳回值
p以獲取說明。
- 傳回:
- pint 的 iterable
對於沿
axis的每個步驟,最短路徑的座標。如果output_indexlist為 True,則路徑會以索引到arr的 n 維元組列表的形式傳回。如果為 False,則路徑會以陣列的形式傳回,其中列出沿軸維度的每個步驟的非軸維度上的路徑座標。也就是說,p.shape == (arr.shape[axis], arr.ndim-1),但 p 在傳回之前會被壓縮,所以如果arr.ndim == 2,則p.shape == (arr.shape[axis],)- costfloat
路徑成本。這是沿路徑的所有差異的絕對總和。
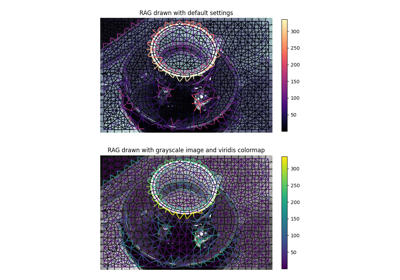
- skimage.graph.show_rag(labels, rag, image, border_color='black', edge_width=1.5, edge_cmap='magma', img_cmap='bone', in_place=True, ax=None)[原始碼]#
在影像上顯示區域鄰接圖。
給定一個標記的影像及其對應的 RAG,在具有指定顏色的影像上顯示 RAG 的節點和邊。邊會顯示在影像中 2 個相鄰區域的質心之間。
- 參數:
- labelsndarray,形狀 (M, N)
已標記的影像。
- ragRAG
區域鄰接圖。
- imagendarray,形狀 (M, N[, 3])
輸入影像。如果
colormap為None,則影像應為 RGB 格式。- border_color顏色規格,可選
繪製區域之間邊界的顏色。
- edge_widthfloat,可選
繪製 RAG 邊緣的粗細。
- edge_cmap
matplotlib.colors.Colormap,可選 用於繪製邊的任何 matplotlib 色彩映射。
- img_cmap
matplotlib.colors.Colormap,可選 用於繪製影像的任何 matplotlib 色彩映射。如果設定為
None,則影像會以原始方式繪製。- in_placebool,可選
如果設定,則 RAG 會就地修改。對於每個節點
n,此函數會設定一個新的屬性rag.nodes[n]['centroid']。- ax
matplotlib.axes.Axes,可選 要在其上繪圖的軸。如果未指定,則會建立新的軸並在其上繪圖。
- 傳回:
- lc
matplotlib.collections.LineCollection 代表圖邊緣的線集合。可以將其傳遞給
matplotlib.figure.Figure.colorbar()函數。
- lc
範例
>>> from skimage import data, segmentation, graph >>> import matplotlib.pyplot as plt >>> >>> img = data.coffee() >>> labels = segmentation.slic(img) >>> g = graph.rag_mean_color(img, labels) >>> lc = graph.show_rag(labels, g, img) >>> cbar = plt.colorbar(lc)
- class skimage.graph.MCP(costs, offsets=None, fully_connected=True, sampling=None)#
基底:
object用於尋找通過給定 n 維成本陣列的最小成本路徑的類別。
給定一個 n 維成本陣列,此類別可用於尋找通過該陣列,從任何一組點到任何另一組點的最低成本路徑。基本用法是初始化類別並使用一個或多個起始索引(和可選的結束索引列表)調用 find_costs()。之後,多次調用 traceback() 以尋找從任何給定的結束位置到最近起始索引的路徑。可以通過重複調用 find_costs() 來找到通過相同成本陣列的新路徑。
路徑的成本僅簡單地計算為路徑上每個點的
costs陣列值的總和。另一方面,MCP_Geometric 類別考慮到對角移動與軸向移動的長度不同,並相應地加權路徑成本。具有無限或負成本的陣列元素會被忽略,累積成本溢位至無限的路徑也會被忽略。
- 參數:
- costsndarray
- offsets可迭代物件,選用
偏移元組的列表:每個偏移指定從給定的 n 維位置的有效移動。如果未提供,則會使用 make_offsets() 函數,並根據
fully_connected參數值,建立對應於單連通或完全連通 n 維鄰域的偏移量。- fully_connected布林值,選用
如果沒有提供
offsets,則此參數決定產生的鄰域的連通性。如果為 true,則路徑可能會沿著costs陣列的元素之間的對角線移動;否則只允許軸向移動。- sampling元組,選用
針對每個維度,指定兩個單元格/體素之間的距離。如果未給定或為 None,則假設距離為單位距離。
- 屬性:
- __init__(costs, offsets=None, fully_connected=True, sampling=None)#
請參閱類別文件。
- find_costs(starts, ends=None, find_all_ends=True, max_coverage=1.0, max_cumulative_cost=None, max_cost=None)#
尋找從給定起點到目標點的最低成本路徑。
此方法會找到從任何一個指定的起點到指定的終點索引的最低成本路徑。如果沒有給定終點位置,則會找到到成本陣列中每個位置的最低成本路徑。
- 參數:
- starts可迭代物件
n 維起始索引的列表(其中 n 是
costs陣列的維度)。將會找到到最近/最便宜的起點的最低成本路徑。- ends可迭代物件,選用
n 維結束索引的列表。
- find_all_ends布林值,選用
如果為「True」(預設值),則會找到到每個指定終點位置的最低成本路徑;否則,當找到到任何終點位置的路徑時,演算法將會停止。(如果沒有指定
ends,則此參數無效。)
- 傳回:
- cumulative_costsndarray
形狀與
costs陣列相同;此陣列記錄從最近/最便宜的起始索引到每個考慮的索引的最低成本路徑。(如果指定了ends,則不一定會考慮陣列中的所有元素:未評估的位置的累積成本為無限大。如果find_all_ends為「False」,則只有一個指定的終點位置會具有有限的累積成本。)- tracebackndarray
形狀與
costs陣列相同;此陣列包含從其前一個索引到任何給定索引的偏移量。偏移索引會索引到offsets屬性,該屬性是一個 n 維偏移量陣列。在 2 維的情況下,如果 offsets[traceback[x, y]] 是 (-1, -1),則表示在到某個起始位置的最低成本路徑中,[x, y] 的前一個索引是 [x+1, y+1]。請注意,如果 offset_index 為 -1,則表示未考慮給定的索引。
- goal_reached(index, cumcost)#
int goal_reached(int index, float cumcost) 這個方法會在每次從堆積彈出索引之後,且在檢查鄰居之前呼叫。
可以重載這個方法,以修改 MCP 演算法的行為。例如,可以在達到特定累積成本時,或當前沿離種子點達到特定距離時停止演算法。
如果演算法不應檢查目前點的鄰居,則這個方法應傳回 1;如果演算法現在已完成,則應傳回 2。
- offsets#
- traceback(end)#
追蹤透過預先計算的回溯陣列的最低成本路徑。
這個方便的函式會從提供給 find_costs() 的其中一個起始索引重建到給定終點位置的最低成本路徑,而 find_costs() 必須先前已經呼叫過。在執行 find_costs() 之後,可以根據需要多次呼叫這個函式。
- 參數:
- enditerable
指向
costs陣列的 n 維索引。
- 傳回:
- tracebackn 維元組的列表
指向
costs陣列的索引列表,從傳遞給 find_costs() 的其中一個起始位置開始,到給定的end索引結束。這些索引指定從任何給定起始索引到end索引的最低成本路徑。(該路徑的總成本可以從 find_costs() 傳回的cumulative_costs陣列中讀取。)
- class skimage.graph.MCP_Connect(costs, offsets=None, fully_connected=True)#
基礎類別:
MCP使用距離加權的最小成本函數連接源點。
從每個種子點同時成長一個前沿,同時也會追蹤前沿的來源。當兩個前沿相遇時,會呼叫 create_connection()。這個方法必須重載,以便以適合應用程式的方式處理找到的邊緣。
- __init__(*args, **kwargs)#
- create_connection(id1, id2, tb1, tb2, cost1, cost2)#
create_connection id1, id2, pos1, pos2, cost1, cost2)
重載這個方法,以追蹤在 MCP 處理期間找到的連線。請注意,可能會多次找到具有相同 id 的連線(但具有不同的位置和成本)。
在呼叫這個方法時,兩個點都已「凍結」,並且 MCP 演算法不會再次訪問。
- 參數:
- id1整數
第一個鄰居的來源種子點 id。
- id2整數
第二個鄰居的來源種子點 id。
- pos1元組
連線中第一個鄰居的索引。
- pos2元組
連線中第二個鄰居的索引。
- cost1浮點數
pos1的累積成本。- cost2浮點數
pos2的累積成本。
- find_costs(starts, ends=None, find_all_ends=True, max_coverage=1.0, max_cumulative_cost=None, max_cost=None)#
尋找從給定起點到目標點的最低成本路徑。
此方法會找到從任何一個指定的起點到指定的終點索引的最低成本路徑。如果沒有給定終點位置,則會找到到成本陣列中每個位置的最低成本路徑。
- 參數:
- starts可迭代物件
n 維起始索引的列表(其中 n 是
costs陣列的維度)。將會找到到最近/最便宜的起點的最低成本路徑。- ends可迭代物件,選用
n 維結束索引的列表。
- find_all_ends布林值,選用
如果為「True」(預設值),則會找到到每個指定終點位置的最低成本路徑;否則,當找到到任何終點位置的路徑時,演算法將會停止。(如果沒有指定
ends,則此參數無效。)
- 傳回:
- cumulative_costsndarray
形狀與
costs陣列相同;此陣列記錄從最近/最便宜的起始索引到每個考慮的索引的最低成本路徑。(如果指定了ends,則不一定會考慮陣列中的所有元素:未評估的位置的累積成本為無限大。如果find_all_ends為「False」,則只有一個指定的終點位置會具有有限的累積成本。)- tracebackndarray
與
costs陣列形狀相同的陣列;此陣列包含從其前一個索引到任何給定索引的偏移量。偏移量索引會索引到offsets屬性,該屬性是一個 n 維偏移量陣列。在 2 維情況下,如果 offsets[traceback[x, y]] 是 (-1, -1),則表示 [x, y] 在到達某個起始位置的最小成本路徑中的前一個位置是 [x+1, y+1]。請注意,如果 offset_index 是 -1,則表示未考慮給定索引。
- goal_reached(index, cumcost)#
int goal_reached(int index, float cumcost) 這個方法會在每次從堆積彈出索引之後,且在檢查鄰居之前呼叫。
可以重載這個方法,以修改 MCP 演算法的行為。例如,可以在達到特定累積成本時,或當前沿離種子點達到特定距離時停止演算法。
如果演算法不應檢查目前點的鄰居,則這個方法應傳回 1;如果演算法現在已完成,則應傳回 2。
- offsets#
- traceback(end)#
追蹤透過預先計算的回溯陣列的最低成本路徑。
這個方便的函式會從提供給 find_costs() 的其中一個起始索引重建到給定終點位置的最低成本路徑,而 find_costs() 必須先前已經呼叫過。在執行 find_costs() 之後,可以根據需要多次呼叫這個函式。
- 參數:
- enditerable
指向
costs陣列的 n 維索引。
- 傳回:
- tracebackn 維元組的列表
指向
costs陣列的索引列表,從傳遞給 find_costs() 的其中一個起始位置開始,到給定的end索引結束。這些索引指定從任何給定起始索引到end索引的最低成本路徑。(該路徑的總成本可以從 find_costs() 傳回的cumulative_costs陣列中讀取。)
- class skimage.graph.MCP_Flexible(costs, offsets=None, fully_connected=True)#
基礎類別:
MCP尋找通過 N 維成本陣列的最小成本路徑。
請參閱 MCP 的文件以了解完整詳細資訊。此類別與 MCP 的不同之處在於,可以覆寫數個方法(來自純 Python),以修改演算法的行為和/或建立基於 MCP 的自訂演算法。請注意,goal_reached 也可以在 MCP 類別中被覆寫。
- __init__(costs, offsets=None, fully_connected=True, sampling=None)#
請參閱類別文件。
- examine_neighbor(index, new_index, offset_length)#
一旦兩個節點都被凍結,此方法會針對每一對相鄰節點呼叫一次。
可以覆寫此方法,以取得相鄰節點的資訊,和/或修改 MCP 演算法的行為。其中一個範例是 MCP_Connect 類別,它使用此勾點檢查相遇的邊界。
- find_costs(starts, ends=None, find_all_ends=True, max_coverage=1.0, max_cumulative_cost=None, max_cost=None)#
尋找從給定起點到目標點的最低成本路徑。
此方法會找到從任何一個指定的起點到指定的終點索引的最低成本路徑。如果沒有給定終點位置,則會找到到成本陣列中每個位置的最低成本路徑。
- 參數:
- starts可迭代物件
n 維起始索引的列表(其中 n 是
costs陣列的維度)。將會找到到最近/最便宜的起點的最低成本路徑。- ends可迭代物件,選用
n 維結束索引的列表。
- find_all_ends布林值,選用
如果為「True」(預設值),則會找到到每個指定終點位置的最低成本路徑;否則,當找到到任何終點位置的路徑時,演算法將會停止。(如果沒有指定
ends,則此參數無效。)
- 傳回:
- cumulative_costsndarray
形狀與
costs陣列相同;此陣列記錄從最近/最便宜的起始索引到每個考慮的索引的最低成本路徑。(如果指定了ends,則不一定會考慮陣列中的所有元素:未評估的位置的累積成本為無限大。如果find_all_ends為「False」,則只有一個指定的終點位置會具有有限的累積成本。)- tracebackndarray
與
costs陣列形狀相同的陣列;此陣列包含從其前一個索引到任何給定索引的偏移量。偏移量索引會索引到offsets屬性,該屬性是一個 n 維偏移量陣列。在 2 維情況下,如果 offsets[traceback[x, y]] 是 (-1, -1),則表示 [x, y] 在到達某個起始位置的最小成本路徑中的前一個位置是 [x+1, y+1]。請注意,如果 offset_index 是 -1,則表示未考慮給定索引。
- goal_reached(index, cumcost)#
int goal_reached(int index, float cumcost) 這個方法會在每次從堆積彈出索引之後,且在檢查鄰居之前呼叫。
可以重載這個方法,以修改 MCP 演算法的行為。例如,可以在達到特定累積成本時,或當前沿離種子點達到特定距離時停止演算法。
如果演算法不應檢查目前點的鄰居,則這個方法應傳回 1;如果演算法現在已完成,則應傳回 2。
- offsets#
- traceback(end)#
追蹤透過預先計算的回溯陣列的最低成本路徑。
這個方便的函式會從提供給 find_costs() 的其中一個起始索引重建到給定終點位置的最低成本路徑,而 find_costs() 必須先前已經呼叫過。在執行 find_costs() 之後,可以根據需要多次呼叫這個函式。
- 參數:
- enditerable
指向
costs陣列的 n 維索引。
- 傳回:
- tracebackn 維元組的列表
指向
costs陣列的索引列表,從傳遞給 find_costs() 的其中一個起始位置開始,到給定的end索引結束。這些索引指定從任何給定起始索引到end索引的最低成本路徑。(該路徑的總成本可以從 find_costs() 傳回的cumulative_costs陣列中讀取。)
- travel_cost(old_cost, new_cost, offset_length)#
此方法計算從目前節點移動到下一個節點的行進成本。預設實作會傳回 new_cost。覆寫此方法以調整演算法的行為。
- update_node(index, new_index, offset_length)#
當節點更新時(在 new_index 被推送至堆積且 traceback 對應更新之後),會呼叫此方法。
可以覆寫此方法,以追蹤特定演算法實作使用的其他陣列。例如,MCP_Connect 類別使用它來更新 id 對應。
- class skimage.graph.MCP_Geometric(costs, offsets=None, fully_connected=True)#
基礎類別:
MCP尋找通過 n 維成本陣列的距離加權最小成本路徑。
請參閱 MCP 的文件以了解完整詳細資訊。此類別與 MCP 的不同之處在於,路徑的成本不只是沿著該路徑的成本總和。
相反地,此類別假設 costs 陣列在每個位置都包含穿過該位置的單位距離行進「成本」。例如,假設從 (1, 1) 到 (1, 2) 的移動(在 2 維中)起始於像素 (1, 1) 的中心,並終止於 (1, 2) 的中心。整個移動的距離為 1,一半穿過 (1, 1),一半穿過 (1, 2);因此,該移動的成本為
(1/2)*costs[1,1] + (1/2)*costs[1,2]。另一方面,從 (1, 1) 到 (2, 2) 的移動是沿著對角線,長度為 sqrt(2)。此移動的一半在像素 (1, 1) 內,另一半在 (2, 2) 內,因此此移動的成本計算為
(sqrt(2)/2)*costs[1,1] + (sqrt(2)/2)*costs[2,2]。使用大於 1 的偏移量時,這些計算沒有太多意義。請使用
sampling引數,以處理異向性資料。- __init__(costs, offsets=None, fully_connected=True, sampling=None)#
請參閱類別文件。
- find_costs(starts, ends=None, find_all_ends=True, max_coverage=1.0, max_cumulative_cost=None, max_cost=None)#
尋找從給定起點到目標點的最低成本路徑。
此方法會找到從任何一個指定的起點到指定的終點索引的最低成本路徑。如果沒有給定終點位置,則會找到到成本陣列中每個位置的最低成本路徑。
- 參數:
- starts可迭代物件
n 維起始索引的列表(其中 n 是
costs陣列的維度)。將會找到到最近/最便宜的起點的最低成本路徑。- ends可迭代物件,選用
n 維結束索引的列表。
- find_all_ends布林值,選用
如果為「True」(預設值),則會找到到每個指定終點位置的最低成本路徑;否則,當找到到任何終點位置的路徑時,演算法將會停止。(如果沒有指定
ends,則此參數無效。)
- 傳回:
- cumulative_costsndarray
形狀與
costs陣列相同;此陣列記錄從最近/最便宜的起始索引到每個考慮的索引的最低成本路徑。(如果指定了ends,則不一定會考慮陣列中的所有元素:未評估的位置的累積成本為無限大。如果find_all_ends為「False」,則只有一個指定的終點位置會具有有限的累積成本。)- tracebackndarray
與
costs陣列形狀相同的陣列;此陣列包含從其前一個索引到任何給定索引的偏移量。偏移量索引會索引到offsets屬性,該屬性是一個 n 維偏移量陣列。在 2 維情況下,如果 offsets[traceback[x, y]] 是 (-1, -1),則表示 [x, y] 在到達某個起始位置的最小成本路徑中的前一個位置是 [x+1, y+1]。請注意,如果 offset_index 是 -1,則表示未考慮給定索引。
- goal_reached(index, cumcost)#
int goal_reached(int index, float cumcost) 這個方法會在每次從堆積彈出索引之後,且在檢查鄰居之前呼叫。
可以重載這個方法,以修改 MCP 演算法的行為。例如,可以在達到特定累積成本時,或當前沿離種子點達到特定距離時停止演算法。
如果演算法不應檢查目前點的鄰居,則這個方法應傳回 1;如果演算法現在已完成,則應傳回 2。
- offsets#
- traceback(end)#
追蹤透過預先計算的回溯陣列的最低成本路徑。
這個方便的函式會從提供給 find_costs() 的其中一個起始索引重建到給定終點位置的最低成本路徑,而 find_costs() 必須先前已經呼叫過。在執行 find_costs() 之後,可以根據需要多次呼叫這個函式。
- 參數:
- enditerable
指向
costs陣列的 n 維索引。
- 傳回:
- tracebackn 維元組的列表
指向
costs陣列的索引列表,從傳遞給 find_costs() 的其中一個起始位置開始,到給定的end索引結束。這些索引指定從任何給定起始索引到end索引的最低成本路徑。(該路徑的總成本可以從 find_costs() 傳回的cumulative_costs陣列中讀取。)
- class skimage.graph.RAG(label_image=None, connectivity=1, data=None, **attr)[source]#
基底類別:
Graph影像的區域鄰接圖 (RAG),是
networkx.Graph的子類別。- 參數:
- label_image整數陣列
一個初始分割,每個區域標記為不同的整數。
label_image中每個唯一的值都會對應到圖中的一個節點。- connectivity整數,介於 {1, …,
label_image.ndim},可選 label_image中像素之間的連通性。對於 2D 影像,連通性為 1 對應到上下左右的直接鄰居,而連通性為 2 也包含對角線鄰居。請參閱scipy.ndimage.generate_binary_structure()。- data
networkx.Graph規格,可選 要傳遞給
networkx.Graph建構子的初始或額外邊。有效的邊規格包括邊列表(元組列表)、NumPy 陣列和 SciPy 稀疏矩陣。- **attr關鍵字參數,可選
要新增到圖中的其他屬性。
- __init__(label_image=None, connectivity=1, data=None, **attr)[source]#
使用邊、名稱或圖屬性初始化圖。
- 參數:
- incoming_graph_data輸入圖(可選,預設值:None)
用於初始化圖的資料。如果為 None(預設值),則會建立一個空圖。資料可以是邊列表或任何 NetworkX 圖物件。如果安裝了對應的可選 Python 套件,資料也可以是 2D NumPy 陣列、SciPy 稀疏陣列或 PyGraphviz 圖。
- attr關鍵字參數,可選(預設值 = 無屬性)
要以 key=value 配對方式新增至圖的屬性。
另請參閱
轉換
範例
>>> G = nx.Graph() # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G = nx.Graph(name="my graph") >>> e = [(1, 2), (2, 3), (3, 4)] # list of edges >>> G = nx.Graph(e)
可以指派任意的圖屬性配對(key=value)
>>> G = nx.Graph(e, day="Friday") >>> G.graph {'day': 'Friday'}
- add_edges_from(ebunch_to_add, **attr)[source]#
新增 ebunch_to_add 中的所有邊。
- 參數:
- ebunch_to_add邊的容器
容器中給定的每個邊都將新增到圖中。邊必須給定為 2 元組 (u, v) 或 3 元組 (u, v, d),其中 d 是包含邊資料的字典。
- attr關鍵字參數,可選
可以使用關鍵字參數指派邊資料(或標籤或物件)。
另請參閱
add_edge新增單一邊
add_weighted_edges_from新增加權邊的便捷方法
註解
新增相同的邊兩次沒有效果,但每次新增重複邊時,任何邊資料都會更新。
ebunch 中指定的邊屬性優先於通過關鍵字參數指定的屬性。
從迭代器新增邊到正在變更的圖時,可能會引發
RuntimeError,訊息為:RuntimeError: dictionary changed size during iteration。當圖的基礎字典在迭代期間被修改時,就會發生這種情況。若要避免此錯誤,請將迭代器評估為一個單獨的物件,例如,使用list(iterator_of_edges),並將此物件傳遞給G.add_edges_from。範例
>>> G = nx.Graph() # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.add_edges_from([(0, 1), (1, 2)]) # using a list of edge tuples >>> e = zip(range(0, 3), range(1, 4)) >>> G.add_edges_from(e) # Add the path graph 0-1-2-3
將資料關聯到邊
>>> G.add_edges_from([(1, 2), (2, 3)], weight=3) >>> G.add_edges_from([(3, 4), (1, 4)], label="WN2898")
如果使用迭代器來修改同一個圖,請評估該迭代器
>>> G = nx.Graph([(1, 2), (2, 3), (3, 4)]) >>> # Grow graph by one new node, adding edges to all existing nodes. >>> # wrong way - will raise RuntimeError >>> # G.add_edges_from(((5, n) for n in G.nodes)) >>> # correct way - note that there will be no self-edge for node 5 >>> G.add_edges_from(list((5, n) for n in G.nodes))
- add_nodes_from(nodes_for_adding, **attr)[source]#
新增多個節點。
- 參數:
- nodes_for_adding可迭代的容器
節點的容器(列表、字典、集合等)。或 (節點、屬性字典) 元組的容器。節點屬性會使用屬性字典進行更新。
- attr關鍵字參數,可選(預設值 = 無屬性)
更新 nodes 中所有節點的屬性。節點中指定為元組的節點屬性優先於通過關鍵字參數指定的屬性。
另請參閱
註解
從迭代器新增節點到正在變更的圖時,可能會引發
RuntimeError,訊息為:RuntimeError: dictionary changed size during iteration。當圖的基礎字典在迭代期間被修改時,就會發生這種情況。若要避免此錯誤,請將迭代器評估為一個單獨的物件,例如,使用list(iterator_of_nodes),並將此物件傳遞給G.add_nodes_from。範例
>>> G = nx.Graph() # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.add_nodes_from("Hello") >>> K3 = nx.Graph([(0, 1), (1, 2), (2, 0)]) >>> G.add_nodes_from(K3) >>> sorted(G.nodes(), key=str) [0, 1, 2, 'H', 'e', 'l', 'o']
使用關鍵字來更新每個節點的特定節點屬性。
>>> G.add_nodes_from([1, 2], size=10) >>> G.add_nodes_from([3, 4], weight=0.4)
使用 (節點、attrdict) 元組來更新特定節點的屬性。
>>> G.add_nodes_from([(1, dict(size=11)), (2, {"color": "blue"})]) >>> G.nodes[1]["size"] 11 >>> H = nx.Graph() >>> H.add_nodes_from(G.nodes(data=True)) >>> H.nodes[1]["size"] 11
如果使用迭代器來修改同一個圖,請評估該迭代器
>>> G = nx.Graph([(0, 1), (1, 2), (3, 4)]) >>> # wrong way - will raise RuntimeError >>> # G.add_nodes_from(n + 1 for n in G.nodes) >>> # correct way >>> G.add_nodes_from(list(n + 1 for n in G.nodes))
- add_weighted_edges_from(ebunch_to_add, weight='weight', **attr)[source]#
在
ebunch_to_add中新增帶有指定權重屬性的加權邊- 參數:
- ebunch_to_add邊的容器
清單或容器中給定的每個邊都將新增到圖中。邊必須給定為 3 元組 (u, v, w),其中 w 是一個數字。
- weight字串,可選(預設值 = 'weight')
要新增的邊權重的屬性名稱。
- attr關鍵字參數,可選(預設值 = 無屬性)
要為所有邊新增/更新的邊屬性。
另請參閱
add_edge新增單一邊
add_edges_from新增多個邊
註解
針對 Graph/DiGraph 新增相同的邊兩次只會更新邊資料。對於 MultiGraph/MultiDiGraph,會儲存重複的邊。
從迭代器新增邊到正在變更的圖時,可能會引發
RuntimeError,訊息為:RuntimeError: dictionary changed size during iteration。當圖的基礎字典在迭代期間被修改時,就會發生這種情況。若要避免此錯誤,請將迭代器評估為一個單獨的物件,例如,使用list(iterator_of_edges),並將此物件傳遞給G.add_weighted_edges_from。範例
>>> G = nx.Graph() # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.add_weighted_edges_from([(0, 1, 3.0), (1, 2, 7.5)])
在傳遞邊的迭代器之前先評估它
>>> G = nx.Graph([(1, 2), (2, 3), (3, 4)]) >>> weight = 0.1 >>> # Grow graph by one new node, adding edges to all existing nodes. >>> # wrong way - will raise RuntimeError >>> # G.add_weighted_edges_from(((5, n, weight) for n in G.nodes)) >>> # correct way - note that there will be no self-edge for node 5 >>> G.add_weighted_edges_from(list((5, n, weight) for n in G.nodes))
- property adj#
圖的鄰接物件,保存每個節點的鄰居。
此物件是一個唯讀的類字典結構,具有節點鍵和鄰居字典值。鄰居字典的鍵是鄰居,值是邊資料字典。因此,
G.adj[3][2]['color'] = 'blue'將邊(3, 2)的顏色設定為"blue"。迭代 G.adj 的行為類似於字典。有用的慣用法包括
for nbr, datadict in G.adj[n].items():。鄰居資訊也可透過下標圖來取得。因此,
for nbr, foovalue in G[node].data('foo', default=1):也能運作。對於有向圖,
G.adj保存外向(後繼)資訊。
- adjacency()[原始碼]#
傳回一個迭代器,該迭代器會產生所有節點的 (節點,鄰接字典) 元組。
對於有向圖,僅包含外向的鄰居/鄰接。
- 傳回:
- adj_iter迭代器
一個迭代器,該迭代器會產生圖中所有節點的 (節點,鄰接字典)。
範例
>>> G = nx.path_graph(4) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> [(n, nbrdict) for n, nbrdict in G.adjacency()] [(0, {1: {}}), (1, {0: {}, 2: {}}), (2, {1: {}, 3: {}}), (3, {2: {}})]
- clear()[原始碼]#
從圖中移除所有節點和邊。
這也會移除名稱,以及所有圖、節點和邊的屬性。
範例
>>> G = nx.path_graph(4) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.clear() >>> list(G.nodes) [] >>> list(G.edges) []
- clear_edges()[原始碼]#
從圖中移除所有邊,但不更改節點。
範例
>>> G = nx.path_graph(4) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.clear_edges() >>> list(G.nodes) [0, 1, 2, 3] >>> list(G.edges) []
- property degree#
圖的 DegreeView,使用 G.degree 或 G.degree()。
節點的度數是與該節點相鄰的邊數。加權節點度數是與該節點相連的邊權重的總和。
此物件提供 (節點,度數) 的迭代器,以及查詢單一節點度數的功能。
- 參數:
- nbunch單一節點、容器或所有節點 (預設值 = 所有節點)
此檢視只會報告與這些節點相連的邊。
- weight字串或 None,選用 (預設值 = None)
保存用作權重的數值的邊屬性名稱。若為 None,則每個邊的權重為 1。度數是與該節點相鄰的邊權重總和。
- 傳回:
- DegreeView 或 int
如果要求多個節點 (預設值),則傳回將節點對應至其度數的
DegreeView。如果要求單一節點,則傳回節點的度數,形式為整數。
範例
>>> G = nx.path_graph(4) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.degree[0] # node 0 has degree 1 1 >>> list(G.degree([0, 1, 2])) [(0, 1), (1, 2), (2, 2)]
- edge_subgraph(edges)[原始碼]#
傳回由指定邊所誘導的子圖。
誘導的子圖包含
edges中的每條邊,以及與這些邊的任一條相連的每個節點。- 參數:
- edges可迭代
此圖中邊的可迭代物件。
- 傳回:
- G圖
此圖的邊誘導子圖,具有相同的邊屬性。
註解
傳回的子圖檢視中的圖、邊和節點屬性是指向原始圖中對應屬性的參照。此檢視是唯讀的。
若要建立具有邊或節點屬性複本的子圖完整圖版本,請使用
G.edge_subgraph(edges).copy()
範例
>>> G = nx.path_graph(5) >>> H = G.edge_subgraph([(0, 1), (3, 4)]) >>> list(H.nodes) [0, 1, 3, 4] >>> list(H.edges) [(0, 1), (3, 4)]
- property edges#
圖的 EdgeView,使用 G.edges 或 G.edges()。
edges(self, nbunch=None, data=False, default=None)
EdgeView 提供邊元組的類集合運算,以及邊屬性查詢。呼叫時,它也會提供 EdgeDataView 物件,該物件允許控制對邊屬性的存取 (但不提供類集合運算)。因此,
G.edges[u, v]['color']提供邊(u, v)的 color 屬性值,而for (u, v, c) in G.edges.data('color', default='red'):會迭代所有邊,產生 color 屬性,如果沒有 color 屬性,則預設為'red'。- 參數:
- nbunch單一節點、容器或所有節點 (預設值 = 所有節點)
此檢視只會報告來自這些節點的邊。
- data字串或布林值,選用 (預設值 = False)
在 3 元組 (u, v, ddict[data]) 中傳回的邊屬性。如果為 True,則在 3 元組 (u, v, ddict) 中傳回邊屬性字典。如果為 False,則傳回 2 元組 (u, v)。
- default值,選用 (預設值 = None)
用於不具有所要求屬性的邊的值。僅在 data 不是 True 或 False 時才相關。
- 傳回:
- edgesEdgeView
邊屬性的檢視,通常會迭代邊的 (u, v) 或 (u, v, d) 元組,但也可用於屬性查詢,例如
edges[u, v]['foo']。
註解
nbunch 中不在圖中的節點將被 (靜默) 忽略。對於有向圖,這會傳回外向的邊。
範例
>>> G = nx.path_graph(3) # or MultiGraph, etc >>> G.add_edge(2, 3, weight=5) >>> [e for e in G.edges] [(0, 1), (1, 2), (2, 3)] >>> G.edges.data() # default data is {} (empty dict) EdgeDataView([(0, 1, {}), (1, 2, {}), (2, 3, {'weight': 5})]) >>> G.edges.data("weight", default=1) EdgeDataView([(0, 1, 1), (1, 2, 1), (2, 3, 5)]) >>> G.edges([0, 3]) # only edges from these nodes EdgeDataView([(0, 1), (3, 2)]) >>> G.edges(0) # only edges from node 0 EdgeDataView([(0, 1)])
- fresh_copy()[原始碼]#
傳回具有相同資料結構的全新副本圖。
全新副本沒有節點、邊或圖屬性。它與目前圖的資料結構相同。此方法通常用於建立圖的空白版本。
當使用 networkx v2 對 Graph 進行子類別化時,這是必要的,而且不會導致 v1 的問題。以下是 network 從 1.x 移轉到 2.x 文件中更詳細的資訊
With the new GraphViews (SubGraph, ReversedGraph, etc) you can't assume that ``G.__class__()`` will create a new instance of the same graph type as ``G``. In fact, the call signature for ``__class__`` differs depending on whether ``G`` is a view or a base class. For v2.x you should use ``G.fresh_copy()`` to create a null graph of the correct type---ready to fill with nodes and edges.
- get_edge_data(u, v, default=None)[原始碼]#
傳回與邊 (u, v) 關聯的屬性字典。
這與
G[u][v]相同,但如果邊不存在,則傳回預設值,而不是例外狀況。- 參數:
- u, v節點
- default: 任何 Python 物件 (預設值 = None)
如果找不到邊 (u, v),則要傳回的值。
- 傳回:
- edge_dict字典
邊屬性字典。
範例
>>> G = nx.path_graph(4) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G[0][1] {}
警告:不允許賦值給
G[u][v]。但賦值屬性G[u][v]['foo']是安全的>>> G[0][1]["weight"] = 7 >>> G[0][1]["weight"] 7 >>> G[1][0]["weight"] 7
>>> G = nx.path_graph(4) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.get_edge_data(0, 1) # default edge data is {} {} >>> e = (0, 1) >>> G.get_edge_data(*e) # tuple form {} >>> G.get_edge_data("a", "b", default=0) # edge not in graph, return 0 0
- has_edge(u, v)[原始碼]#
如果邊 (u, v) 存在於圖形中,則回傳 True。
這與
v in G[u]相同,但不會拋出 KeyError 例外。- 參數:
- u, v節點
節點可以是字串或數字等。節點必須是可雜湊的(且不是 None)Python 物件。
- 傳回:
- edge_indbool
如果邊存在於圖形中,則為 True,否則為 False。
範例
>>> G = nx.path_graph(4) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.has_edge(0, 1) # using two nodes True >>> e = (0, 1) >>> G.has_edge(*e) # e is a 2-tuple (u, v) True >>> e = (0, 1, {"weight": 7}) >>> G.has_edge(*e[:2]) # e is a 3-tuple (u, v, data_dictionary) True
以下語法是等效的
>>> G.has_edge(0, 1) True >>> 1 in G[0] # though this gives KeyError if 0 not in G True
- has_node(n)[原始碼]#
如果圖形包含節點 n,則回傳 True。
等同於
n in G- 參數:
- n節點
範例
>>> G = nx.path_graph(3) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.has_node(0) True
使用以下方法更易讀且更簡潔
>>> 0 in G True
- merge_nodes(src, dst, weight_func=<function min_weight>, in_place=True, extra_arguments=None, extra_keywords=None)[原始碼]#
合併節點
src和dst。新的合併節點與
src和dst的所有鄰居相鄰。weight_func用於決定新節點上的邊權重。- 參數:
- src, dstint
要合併的節點。
- weight_func可呼叫物件,選用
用於決定新節點上的邊屬性的函數。對於
src和dst的每個鄰居n,將會以下列方式呼叫weight_func:weight_func(src, dst, n, *extra_arguments, **extra_keywords)。src、dst和n是 RAG 物件中頂點的 ID,而 RAG 物件又是networkx.Graph的子類。它應回傳結果邊的屬性字典。- in_placebool,可選
如果設定為
True,合併的節點具有 IDdst,否則合併的節點具有回傳的新 ID。- extra_arguments序列,選用
傳遞給
weight_func的額外位置參數序列。- extra_keywords字典,選用
傳遞給
weight_func的關鍵字引數字典。
- 傳回:
- idint
新節點的 ID。
註解
如果
in_place是False,則產生的節點具有新 ID,而不是dst。
- property name#
圖形的字串識別符號。
此圖形屬性會出現在屬性字典 G.graph 中,其鍵為字串
"name",以及屬性(技術上為屬性)G.name。這完全由使用者控制。
- nbunch_iter(nbunch=None)[原始碼]#
回傳一個迭代器,該迭代器會迭代 nbunch 中包含且也存在於圖形中的節點。
會檢查 nbunch 中的節點是否為圖形成員,如果不是,則會靜默忽略。
- 參數:
- nbunch單一節點、容器或所有節點 (預設值 = 所有節點)
此檢視只會報告與這些節點相連的邊。
- 傳回:
- niter迭代器
一個迭代器,用於迭代 nbunch 中包含且也存在於圖形中的節點。如果 nbunch 為 None,則迭代圖形中的所有節點。
- 引發:
- NetworkXError
如果 nbunch 不是節點或節點序列。如果 nbunch 中的節點不可雜湊。
另請參閱
Graph.__iter__
註解
當 nbunch 是迭代器時,回傳的迭代器會直接從 nbunch 產生值,當 nbunch 耗盡時會變成耗盡狀態。
若要測試 nbunch 是否為單一節點,即使使用此常式處理之後,也可以使用「if nbunch in self:」。
如果 nbunch 不是節點或(可能為空的)序列/迭代器或 None,則會引發
NetworkXError。此外,如果 nbunch 中的任何物件不可雜湊,則會引發NetworkXError。
- neighbors(n)[原始碼]#
回傳一個迭代器,該迭代器會迭代節點 n 的所有鄰居。
這與
iter(G[n])相同- 參數:
- n節點
圖形中的節點
- 傳回:
- neighbors迭代器
一個迭代器,用於迭代節點 n 的所有鄰居
- 引發:
- NetworkXError
如果節點 n 不在圖形中。
註解
存取鄰居的替代方法是
G.adj[n]或G[n]>>> G = nx.Graph() # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.add_edge("a", "b", weight=7) >>> G["a"] AtlasView({'b': {'weight': 7}}) >>> G = nx.path_graph(4) >>> [n for n in G[0]] [1]
範例
>>> G = nx.path_graph(4) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> [n for n in G.neighbors(0)] [1]
- property nodes#
圖形的 NodeView,如 G.nodes 或 G.nodes()。
可作為
G.nodes用於資料查詢和類集合運算。也可以作為G.nodes(data='color', default=None)來回傳 NodeDataView,該檢視會報告特定的節點資料,但不進行集合運算。它也會呈現類字典介面,G.nodes.items()會迭代(node, nodedata)二元組,而G.nodes[3]['foo']提供節點3的foo屬性值。此外,檢視G.nodes.data('foo')提供每個節點foo屬性的類字典介面。G.nodes.data('foo', default=1)為沒有屬性foo的節點提供預設值。- 參數:
- data字串或布林值,選用 (預設值 = False)
在二元組 (n, ddict[data]) 中回傳的節點屬性。如果為 True,則回傳整個節點屬性字典,格式為 (n, ddict)。如果為 False,則只回傳節點 n。
- default值,選用 (預設值 = None)
用於沒有所要求屬性的節點值。僅在 data 不是 True 或 False 時相關。
- 傳回:
- NodeView
允許對節點執行類似集合的操作,以及節點屬性字典的查找和呼叫以取得 NodeDataView。NodeDataView 會迭代處理
(n, data),且沒有集合操作。NodeView 會迭代處理n並包含集合操作。當呼叫時,如果 data 為 False,則會產生節點的迭代器。否則,會產生 2 元組 (節點、屬性值) 的迭代器,其中屬性是在
data中指定。如果 data 為 True,則屬性會變成整個資料字典。
註解
如果不需要節點資料,則使用運算式
for n in G或list(G)會更簡單且等效。範例
有兩種簡單的方法可以取得圖形中所有節點的列表
>>> G = nx.path_graph(3) >>> list(G.nodes) [0, 1, 2] >>> list(G) [0, 1, 2]
若要取得節點資料以及節點
>>> G.add_node(1, time="5pm") >>> G.nodes[0]["foo"] = "bar" >>> list(G.nodes(data=True)) [(0, {'foo': 'bar'}), (1, {'time': '5pm'}), (2, {})] >>> list(G.nodes.data()) [(0, {'foo': 'bar'}), (1, {'time': '5pm'}), (2, {})]
>>> list(G.nodes(data="foo")) [(0, 'bar'), (1, None), (2, None)] >>> list(G.nodes.data("foo")) [(0, 'bar'), (1, None), (2, None)]
>>> list(G.nodes(data="time")) [(0, None), (1, '5pm'), (2, None)] >>> list(G.nodes.data("time")) [(0, None), (1, '5pm'), (2, None)]
>>> list(G.nodes(data="time", default="Not Available")) [(0, 'Not Available'), (1, '5pm'), (2, 'Not Available')] >>> list(G.nodes.data("time", default="Not Available")) [(0, 'Not Available'), (1, '5pm'), (2, 'Not Available')]
如果某些節點具有屬性,而其餘節點則假設具有預設屬性值,則可以使用
default關鍵字引數從節點/屬性配對建立字典,以保證值永遠不是 None>>> G = nx.Graph() >>> G.add_node(0) >>> G.add_node(1, weight=2) >>> G.add_node(2, weight=3) >>> dict(G.nodes(data="weight", default=1)) {0: 1, 1: 2, 2: 3}
- number_of_edges(u=None, v=None)[來源]#
傳回兩個節點之間的邊數。
- 參數:
- u, v節點,可選 (預設值 = 所有邊)
如果指定 u 和 v,則傳回 u 和 v 之間的邊數。否則傳回所有邊的總數。
- 傳回:
- nedges整數
圖形中的邊數。如果指定節點
u和v,則傳回這些節點之間的邊數。如果圖形是有向圖,則只傳回從u到v的邊數。
另請參閱
範例
對於無向圖,此方法會計算圖形中的邊總數
>>> G = nx.path_graph(4) >>> G.number_of_edges() 3
如果指定兩個節點,則會計算連接這兩個節點的邊總數
>>> G.number_of_edges(0, 1) 1
對於有向圖,此方法可以計算從
u到v的有向邊總數>>> G = nx.DiGraph() >>> G.add_edge(0, 1) >>> G.add_edge(1, 0) >>> G.number_of_edges(0, 1) 1
- number_of_nodes()[來源]#
傳回圖形中的節點數。
- 傳回:
- nnodes整數
圖形中的節點數。
另請參閱
階數相同的方法
__len__相同的方法
範例
>>> G = nx.path_graph(3) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.number_of_nodes() 3
- order()[來源]#
傳回圖形中的節點數。
- 傳回:
- nnodes整數
圖形中的節點數。
另請參閱
number_of_nodes相同的方法
__len__相同的方法
範例
>>> G = nx.path_graph(3) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.order() 3
- remove_edge(u, v)[來源]#
移除 u 和 v 之間的邊。
- 參數:
- u, v節點
移除節點 u 和 v 之間的邊。
- 引發:
- NetworkXError
如果 u 和 v 之間沒有邊。
另請參閱
remove_edges_from移除邊的集合
範例
>>> G = nx.path_graph(4) # or DiGraph, etc >>> G.remove_edge(0, 1) >>> e = (1, 2) >>> G.remove_edge(*e) # unpacks e from an edge tuple >>> e = (2, 3, {"weight": 7}) # an edge with attribute data >>> G.remove_edge(*e[:2]) # select first part of edge tuple
- remove_edges_from(ebunch)[來源]#
移除 ebunch 中指定的所有邊。
- 參數:
- ebunch:邊元組的列表或容器
將從圖形中移除列表或容器中提供的每個邊。邊可以是
2 元組 (u, v) u 和 v 之間的邊。
3 元組 (u, v, k),其中 k 會被忽略。
另請參閱
remove_edge移除單一邊
註解
如果 ebunch 中的邊不在圖形中,則會以靜默方式失敗。
範例
>>> G = nx.path_graph(4) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> ebunch = [(1, 2), (2, 3)] >>> G.remove_edges_from(ebunch)
- remove_node(n)[來源]#
移除節點 n。
移除節點 n 和所有相鄰邊。嘗試移除不存在的節點會引發例外狀況。
- 參數:
- n節點
圖形中的節點
- 引發:
- NetworkXError
如果 n 不在圖形中。
另請參閱
範例
>>> G = nx.path_graph(3) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> list(G.edges) [(0, 1), (1, 2)] >>> G.remove_node(1) >>> list(G.edges) []
- remove_nodes_from(nodes)[來源]#
移除多個節點。
- 參數:
- nodes可迭代的容器
節點的容器 (列表、字典、集合等)。如果容器中的節點不在圖形中,則會以靜默方式忽略。
另請參閱
註解
當從圖形的迭代器中移除節點時,您正在變更,會引發帶有訊息的
RuntimeError:RuntimeError: dictionary changed size during iteration。當在迭代期間修改圖形的基礎字典時,就會發生這種情況。若要避免此錯誤,請將迭代器評估為個別物件,例如使用list(iterator_of_nodes),並將此物件傳遞至G.remove_nodes_from。範例
>>> G = nx.path_graph(3) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> e = list(G.nodes) >>> e [0, 1, 2] >>> G.remove_nodes_from(e) >>> list(G.nodes) []
如果使用迭代器來修改同一個圖,請評估該迭代器
>>> G = nx.Graph([(0, 1), (1, 2), (3, 4)]) >>> # this command will fail, as the graph's dict is modified during iteration >>> # G.remove_nodes_from(n for n in G.nodes if n < 2) >>> # this command will work, since the dictionary underlying graph is not modified >>> G.remove_nodes_from(list(n for n in G.nodes if n < 2))
- size(weight=None)[來源]#
傳回邊數或所有邊權重的總和。
- 參數:
- weight字串或 None,選用 (預設值 = None)
邊屬性,其中包含用作權重的數值。如果為 None,則每個邊的權重為 1。
- 傳回:
- 大小數值
邊數或 (如果提供 weight 關鍵字) 總權重總和。
如果 weight 為 None,則傳回整數。否則,則為浮點數 (或如果權重更一般,則為更一般的數值)。
另請參閱
範例
>>> G = nx.path_graph(4) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.size() 3
>>> G = nx.Graph() # or DiGraph, MultiGraph, MultiDiGraph, etc >>> G.add_edge("a", "b", weight=2) >>> G.add_edge("b", "c", weight=4) >>> G.size() 2 >>> G.size(weight="weight") 6.0
- subgraph(nodes)[來源]#
傳回在
nodes上誘導的子圖的 SubGraph 檢視。圖形的誘導子圖包含
nodes中的節點,以及這些節點之間的邊。- 參數:
- nodes列表、可迭代
節點的容器,將會迭代處理一次。
- 傳回:
- GSubGraph 檢視
圖形的子圖檢視。無法變更圖形結構,但節點/邊屬性可以變更,並與原始圖形共用。
註解
圖形、邊和節點屬性會與原始圖形共用。檢視會排除圖形結構的變更,但屬性的變更會反映在原始圖形中。
若要建立具有其自身邊/節點屬性複本的子圖,請使用:G.subgraph(nodes).copy()
若要將圖形就地縮減為子圖,您可以移除節點:G.remove_nodes_from([n for n in G if n not in set(nodes)])
子圖檢視有時並不是您想要的。在大多數您想要做的不只是簡單地查看誘導邊的情況下,將子圖建立為具有類似程式碼的自身圖形會更有意義
# Create a subgraph SG based on a (possibly multigraph) G SG = G.__class__() SG.add_nodes_from((n, G.nodes[n]) for n in largest_wcc) if SG.is_multigraph(): SG.add_edges_from( (n, nbr, key, d) for n, nbrs in G.adj.items() if n in largest_wcc for nbr, keydict in nbrs.items() if nbr in largest_wcc for key, d in keydict.items() ) else: SG.add_edges_from( (n, nbr, d) for n, nbrs in G.adj.items() if n in largest_wcc for nbr, d in nbrs.items() if nbr in largest_wcc ) SG.graph.update(G.graph)
範例
>>> G = nx.path_graph(4) # or DiGraph, MultiGraph, MultiDiGraph, etc >>> H = G.subgraph([0, 1, 2]) >>> list(H.edges) [(0, 1), (1, 2)]
- to_directed(as_view=False)[來源]#
傳回圖形的有向表示法。
- 傳回:
- GDiGraph
具有相同名稱、相同節點,且每個邊 (u, v, data) 都由兩個有向邊 (u, v, data) 和 (v, u, data) 取代之有向圖。
註解
這會傳回邊、節點和圖形屬性的「深層複製」,其嘗試完全複製所有資料和參考。
這與傳回資料的淺層複製的類似 D=DiGraph(G) 相反。
如需有關淺層和深層複製的詳細資訊,請參閱 Python 複製模組,https://docs.python.org/3/library/copy.html。
警告:如果您已將 Graph 子類化以在資料結構中使用類似字典的物件,則這些變更不會傳輸到此方法建立的 DiGraph。
範例
>>> G = nx.Graph() # or MultiGraph, etc >>> G.add_edge(0, 1) >>> H = G.to_directed() >>> list(H.edges) [(0, 1), (1, 0)]
如果已經有向,則傳回 (深層) 複製
>>> G = nx.DiGraph() # or MultiDiGraph, etc >>> G.add_edge(0, 1) >>> H = G.to_directed() >>> list(H.edges) [(0, 1)]
- to_directed_class()[來源]#
傳回用於空有向複本的類別。
如果您將基底類別子類化,請使用此選項來指定要用於
to_directed()複本的有向類別。
- to_undirected(as_view=False)[原始碼]#
回傳此圖的無向副本。
- 參數:
- as_view布林值(可選,預設為 False)
若為 True,則回傳原始無向圖的視圖。
- 傳回:
- G圖/多重圖
此圖的深層複製。
另請參閱
Graph,copy,add_edge,add_edges_from
註解
這會傳回邊、節點和圖形屬性的「深層複製」,其嘗試完全複製所有資料和參考。
這與類似的
G = nx.DiGraph(D)不同,後者會回傳資料的淺層複製。如需有關淺層和深層複製的詳細資訊,請參閱 Python 複製模組,https://docs.python.org/3/library/copy.html。
警告:如果您已經子類化 DiGraph 以在資料結構中使用類似字典的物件,這些變更不會轉移到此方法建立的 Graph。
範例
>>> G = nx.path_graph(2) # or MultiGraph, etc >>> H = G.to_directed() >>> list(H.edges) [(0, 1), (1, 0)] >>> G2 = H.to_undirected() >>> list(G2.edges) [(0, 1)]
- to_undirected_class()[原始碼]#
回傳用於建立空的無向副本的類別。
如果您將基底類別子類化,請使用此選項來指定要用於
to_directed()複本的有向類別。
- update(edges=None, nodes=None)[原始碼]#
使用節點/邊/圖作為輸入來更新圖。
如同 dict.update,此方法會將圖作為輸入,將該圖的節點和邊添加到此圖中。 它也可以接受兩個輸入:邊和節點。 最後,它可以只接受邊或節點。 若要只指定節點,則必須使用關鍵字
nodes。邊和節點的集合的處理方式與 add_edges_from/add_nodes_from 方法類似。 當迭代時,它們應該產生 2 元組 (u, v) 或 3 元組 (u, v, datadict)。
- 參數:
另請參閱
add_edges_from向圖新增多條邊
add_nodes_from向圖新增多個節點
註解
如果您想使用鄰接結構更新圖,則可以直接從鄰接獲得邊/節點。 以下範例提供了常見情況,您的鄰接可能略有不同,需要對這些範例進行調整
>>> # dict-of-set/list/tuple >>> adj = {1: {2, 3}, 2: {1, 3}, 3: {1, 2}} >>> e = [(u, v) for u, nbrs in adj.items() for v in nbrs] >>> G.update(edges=e, nodes=adj)
>>> DG = nx.DiGraph() >>> # dict-of-dict-of-attribute >>> adj = {1: {2: 1.3, 3: 0.7}, 2: {1: 1.4}, 3: {1: 0.7}} >>> e = [ ... (u, v, {"weight": d}) ... for u, nbrs in adj.items() ... for v, d in nbrs.items() ... ] >>> DG.update(edges=e, nodes=adj)
>>> # dict-of-dict-of-dict >>> adj = {1: {2: {"weight": 1.3}, 3: {"color": 0.7, "weight": 1.2}}} >>> e = [ ... (u, v, {"weight": d}) ... for u, nbrs in adj.items() ... for v, d in nbrs.items() ... ] >>> DG.update(edges=e, nodes=adj)
>>> # predecessor adjacency (dict-of-set) >>> pred = {1: {2, 3}, 2: {3}, 3: {3}} >>> e = [(v, u) for u, nbrs in pred.items() for v in nbrs]
>>> # MultiGraph dict-of-dict-of-dict-of-attribute >>> MDG = nx.MultiDiGraph() >>> adj = { ... 1: {2: {0: {"weight": 1.3}, 1: {"weight": 1.2}}}, ... 3: {2: {0: {"weight": 0.7}}}, ... } >>> e = [ ... (u, v, ekey, d) ... for u, nbrs in adj.items() ... for v, keydict in nbrs.items() ... for ekey, d in keydict.items() ... ] >>> MDG.update(edges=e)
範例
>>> G = nx.path_graph(5) >>> G.update(nx.complete_graph(range(4, 10))) >>> from itertools import combinations >>> edges = ( ... (u, v, {"power": u * v}) ... for u, v in combinations(range(10, 20), 2) ... if u * v < 225 ... ) >>> nodes = [1000] # for singleton, use a container >>> G.update(edges, nodes)