skimage.measure#
影像屬性的測量,例如,區域屬性、輪廓。
以指定的容差近似多邊形鏈。 |
|
通過將函式 |
|
計算表示影像中模糊強度的度量(0 表示無模糊,1 表示最大模糊)。 |
|
傳回影像的(加權)質心。 |
|
計算二值影像中的歐拉特徵數。 |
|
在 2D 陣列中尋找給定等級值的等值輪廓。 |
|
測試指定網格上的點是否在多邊形內。 |
|
計算輸入影像的慣性張量。 |
|
計算影像慣性張量的特徵值。 |
|
通道分割二值遮罩與第二通道分割二值遮罩重疊的部分比例。 |
|
標記整數陣列的連通區域。 |
|
兩個通道之間的曼德斯共定位係數。 |
|
曼德斯重疊係數 |
|
用於尋找 3D 體積資料中表面的行進立方體演算法。 |
|
計算給定頂點和三角形面的表面積。 |
|
計算直到特定階數的所有原始影像矩。 |
|
計算直到特定階數的所有中心影像矩。 |
|
計算直到特定階數的所有原始影像矩。 |
|
計算直到特定階數的所有中心影像矩。 |
|
計算胡氏影像矩集(僅限 2D)。 |
|
計算直到特定階數的所有標準化中心影像矩。 |
|
計算通道中像素強度之間的皮爾森相關係數。 |
|
計算二值影像中所有物件的總周長。 |
|
計算二值影像中所有物件的總克羅夫頓周長。 |
|
測試點是否位於多邊形內。 |
|
傳回沿掃描線測量的影像強度輪廓。 |
|
使用 RANSAC(隨機樣本共識)演算法將模型擬合到資料。 |
|
測量標記影像區域的屬性。 |
|
計算影像屬性並將它們作為與 pandas 相容的表格傳回。 |
|
計算影像的香農熵。 |
|
使用 B 樣條對多邊形曲線進行細分。 |
|
2D 圓的總最小二乘估計器。 |
|
2D 橢圓的總最小二乘估計器。 |
|
N 維直線的總最小二乘估計器。 |
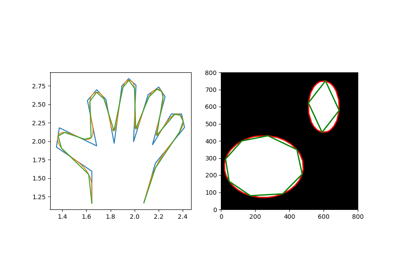
- skimage.measure.approximate_polygon(coords, tolerance)[原始碼]#
以指定的容差近似多邊形鏈。
它基於道格拉斯-普克演算法。
請注意,近似多邊形始終在原始多邊形的凸包內。
- 參數:
- coords(K, 2) 陣列
座標陣列。
- tolerancefloat
從多邊形的原始點到近似多邊形鏈的最大距離。 如果容差為 0,則傳回原始座標陣列。
- 傳回:
- coords(L, 2) 陣列
近似多邊形鏈,其中 L <= K。
參考文獻
- skimage.measure.block_reduce(image, block_size=2, func=<function sum>, cval=0, func_kwargs=None)[原始碼]#
通過將函式
func應用於局部區塊來對影像進行降採樣。此函式對於最大和平均池化等很有用。
- 參數:
- image(M[, …]) ndarray
N 維輸入影像。
- block_sizearray_like 或 int
包含沿每個軸的降採樣整數因數的陣列。 預設的 block_size 為 2。
- func可呼叫
用於計算每個局部區塊傳回值的函式物件。 此函式必須實作
axis參數。 主要函式為numpy.sum、numpy.min、numpy.max、numpy.mean和numpy.median。另請參閱func_kwargs。- cvalfloat
如果影像無法被區塊大小完美整除,則為常數填補值。
- func_kwargsdict
傳遞給
func的關鍵字引數。 對於將 dtype 引數傳遞給np.mean特別有用。 採用輸入的字典,例如:func_kwargs={'dtype': np.float16})。
- 傳回:
- imagendarray
降採樣影像,其維度數與輸入影像相同。
範例
>>> from skimage.measure import block_reduce >>> image = np.arange(3*3*4).reshape(3, 3, 4) >>> image array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]], [[24, 25, 26, 27], [28, 29, 30, 31], [32, 33, 34, 35]]]) >>> block_reduce(image, block_size=(3, 3, 1), func=np.mean) array([[[16., 17., 18., 19.]]]) >>> image_max1 = block_reduce(image, block_size=(1, 3, 4), func=np.max) >>> image_max1 array([[[11]], [[23]], [[35]]]) >>> image_max2 = block_reduce(image, block_size=(3, 1, 4), func=np.max) >>> image_max2 array([[[27], [31], [35]]])
- skimage.measure.blur_effect(image, h_size=11, channel_axis=None, reduce_func=<function max>)[原始碼]#
計算表示影像中模糊強度的度量(0 表示無模糊,1 表示最大模糊)。
- 參數:
- imagendarray
RGB 或灰階 nD 影像。 輸入影像在計算模糊度量之前會轉換為灰階。
- h_sizeint,選用
重新模糊濾波器的大小。
- channel_axisint 或 None,選用
如果為 None,則假設影像為灰階(單通道)。 否則,此參數表示陣列的哪個軸對應於色彩通道。
- reduce_func可呼叫,選用
用於計算沿所有軸的模糊度量聚合的函式。 如果設定為 None,則傳回整個清單,其中第 i 個元素是沿第 i 個軸的模糊度量。
- 傳回:
- blurfloat(0 到 1)或浮點數清單
模糊度量:預設情況下,是沿所有軸的模糊度量的最大值。
備註
h_size必須保持相同的值,以便比較影像之間的結果。 大多數時候,預設大小 (11) 就足夠了。 這表示該度量可以清楚地區分平均 11x11 濾波器以下的模糊; 如果模糊度更高,則該度量仍然可以提供良好的結果,但其值趨向於漸近線。參考文獻
[1]Frederique Crete、Thierry Dolmiere、Patricia Ladret 和 Marina Nicolas “模糊效果:透過新的無參考感知模糊度量的感知和估計” Proc. SPIE 6492,人類視覺和電子成像 XII, 64920I (2007) https://hal.archives-ouvertes.fr/hal-00232709 DOI:10.1117/12.702790

- skimage.measure.centroid(image, *, spacing=None)[原始碼]#
傳回影像的(加權)質心。
- 參數:
- image陣列
輸入影像。
- spacing:浮點數元組,形狀為 (ndim,)
沿影像每個軸的像素間距。
- 傳回:
- center浮點數元組,長度為
image.ndim image中(非零)像素的質心。
- center浮點數元組,長度為
範例
>>> image = np.zeros((20, 20), dtype=np.float64) >>> image[13:17, 13:17] = 0.5 >>> image[10:12, 10:12] = 1 >>> centroid(image) array([13.16666667, 13.16666667])
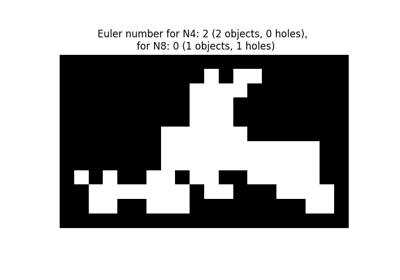
- skimage.measure.euler_number(image, connectivity=None)[原始碼]#
計算二值影像中的歐拉特徵數。
對於 2D 物件,歐拉數是物件數減去孔洞數。 對於 3D 物件,歐拉數是透過物件數加上孔洞數,減去隧道或迴圈數來獲得的。
- 參數:
- image: (M, N[, P]) ndarray
輸入影像。 如果影像不是二值的,則大於零的所有值都視為物件。
- connectivityint,選用
將像素/體素視為鄰居時,要考慮的最大正交跳躍次數。可接受的值範圍為 1 到 input.ndim。如果為
None,則使用input.ndim的完整連通性。二維影像定義 4 或 8 鄰域(連通性分別為 1 和 2)。三維影像定義 6 或 26 鄰域(連通性分別為 1 和 3)。未定義連通性 2。
- 傳回:
- euler_numberint
影像中所有物件的歐拉特徵數。
備註
歐拉特徵數是一個整數,描述輸入影像中所有物件集合的拓撲結構。如果物件是 4 連通,則背景是 8 連通,反之亦然。
歐拉特徵數的計算基於離散空間中的積分幾何公式。實際上,會建構一個鄰域配置,並為每個配置應用一個 LUT。使用的係數是 Ohser 等人的係數。
計算多個連通性的歐拉特徵數可能很有用。不同連通性結果之間的較大相對差異表示影像解析度(相對於物件和孔洞的大小)太低。
參考文獻
[1]S. Rivollier. Analyse d’image geometrique et morphometrique par diagrammes de forme et voisinages adaptatifs generaux. PhD thesis, 2010. Ecole Nationale Superieure des Mines de Saint-Etienne. https://tel.archives-ouvertes.fr/tel-00560838
[2]Ohser J., Nagel W., Schladitz K. (2002) The Euler Number of Discretized Sets - On the Choice of Adjacency in Homogeneous Lattices. In: Mecke K., Stoyan D. (eds) Morphology of Condensed Matter. Lecture Notes in Physics, vol 600. Springer, Berlin, Heidelberg.
範例
>>> import numpy as np >>> SAMPLE = np.zeros((100,100,100)); >>> SAMPLE[40:60, 40:60, 40:60]=1 >>> euler_number(SAMPLE) 1... >>> SAMPLE[45:55,45:55,45:55] = 0; >>> euler_number(SAMPLE) 2... >>> SAMPLE = np.array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0], ... [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0], ... [1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0], ... [0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1], ... [0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1]]) >>> euler_number(SAMPLE) # doctest: 0 >>> euler_number(SAMPLE, connectivity=1) # doctest: 2
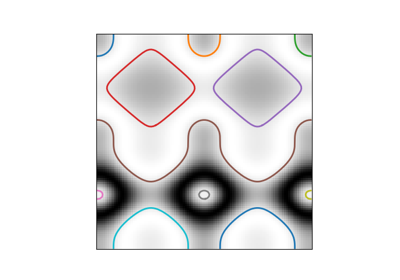
- skimage.measure.find_contours(image, level=None, fully_connected='low', positive_orientation='low', *, mask=None)[原始碼]#
在 2D 陣列中尋找給定等級值的等值輪廓。
使用「行進方塊」方法來計算特定水平值的輸入二維陣列的等值輪廓。陣列值會線性內插,以提供更好的輸出輪廓精確度。
- 參數:
- image(M, N) 雙精度 ndarray
要在其中尋找輪廓的輸入影像。
- levelfloat,選用
沿著陣列中尋找輪廓的值。預設情況下,水平值設定為 (max(image) + min(image)) / 2
在 0.18 版中變更:此參數現在是選用的。
- fully_connectedstr, {'low', 'high'}
指出是否要將低於指定水平值的陣列元素視為完全連通(因此高於該值的元素將僅以面連通),反之亦然。(詳情請參閱下方註解。)
- positive_orientationstr, {'low', 'high'}
指出輸出輪廓是否會在低值或高值元素的島嶼周圍產生正向多邊形。如果為 'low',則輪廓將沿著低於等值元素的逆時針方向纏繞。或者,這表示低值元素始終位於輪廓的左側。(詳情請參閱下方。)
- mask(M, N) bool 的 ndarray 或 None
一個布林遮罩,True 表示我們要繪製輪廓的位置。請注意,NaN 值始終會排除在考量區域之外(無論
array為何值,都會將mask設定為False)。
- 傳回:
- contours(K, 2) ndarray 的清單
每個輪廓都是沿著輪廓的
(列, 欄)座標的 ndarray。
備註
行進方塊演算法是行進立方體演算法的特例 [1]。此處提供簡單的說明
https://users.polytech.unice.fr/~lingrand/MarchingCubes/algo.html
行進方塊演算法中存在一個不明確的情況:當給定的
2 x 2元素正方形有兩個高值元素和兩個低值元素,且每對元素在對角相鄰時。(其中高值和低值是相對於所尋找的輪廓值而言。)在這種情況下,高值元素可以透過分隔低值元素的細地峽「連接在一起」,反之亦然。當元素跨對角線連接在一起時,它們會被視為「完全連通」(也稱為「面+頂點連通」或「8 連通」)。只有高值或低值元素可以是完全連通,另一組將被視為「面連通」或「4 連通」。預設情況下,低值元素會被視為完全連通;這可以使用 'fully_connected' 參數來變更。無法保證輸出輪廓是封閉的:與陣列邊緣或遮蔽區域相交的輪廓(遮罩為 False 或陣列為 NaN 的位置)將保持開啟狀態。所有其他輪廓都將會是封閉的。(可以透過檢查起始點是否與終點相同來測試輪廓的封閉性。)
輪廓是有方向性的。預設情況下,低於輪廓值的陣列值位於輪廓的左側,高於輪廓值的陣列值位於輪廓的右側。這表示輪廓將在低值像素島嶼周圍以逆時針方向(即「正向」)纏繞。可以使用 'positive_orientation' 參數來變更此行為。
輸出清單中輪廓的順序由輪廓中最小
x,y(依字典順序)座標的位置決定。這是輸入陣列的走訪方式的副作用,但可以信賴。警告
陣列座標/值假設是指陣列元素的中心。以一個簡單的範例輸入為例:
[0, 1]。在此陣列中 0.5 的內插位置是 0 元素(位於x=0)和 1 元素(位於x=1)的中間,因此會落在x=0.5。這表示為了找到合理的輪廓,最好在預期的「亮」值和「暗」值之間找到輪廓。特別是,在給定二元化陣列的情況下,請勿選擇在陣列的低值或高值處尋找輪廓。這通常會產生退化的輪廓,尤其是在單個陣列元素寬的結構周圍。相反地,請選擇中間值,如上所述。
參考文獻
[1]Lorensen, William and Harvey E. Cline. Marching Cubes: A High Resolution 3D Surface Construction Algorithm. Computer Graphics (SIGGRAPH 87 Proceedings) 21(4) July 1987, p. 163-170). DOI:10.1145/37401.37422
範例
>>> a = np.zeros((3, 3)) >>> a[0, 0] = 1 >>> a array([[1., 0., 0.], [0., 0., 0.], [0., 0., 0.]]) >>> find_contours(a, 0.5) [array([[0. , 0.5], [0.5, 0. ]])]

- skimage.measure.grid_points_in_poly(shape, verts, binarize=True)[原始碼]#
測試指定網格上的點是否在多邊形內。
針對格線上的每個
(r, c)座標,即(0, 0)、(0, 1)等,測試該點是否位於多邊形內部。您可以使用
binarize旗標來控制輸出類型。請參閱其文件以取得更多詳細資料。- 參數:
- shapetuple (M, N)
格線的形狀。
- verts(V, 2) 陣列
指定多邊形的 V 個頂點,依順時針或逆時針方向排序。第一個點可能會(但不需要)重複。
- binarize:bool
如果為
True,則函式的輸出為布林遮罩。否則,它是一個標記陣列。標籤為:O - 外部,1 - 內部,2 - 頂點,3 - 邊緣。
- 傳回:
- mask(M, N) ndarray
如果
binarize為 True,則輸出為布林遮罩。True 表示對應的像素落在多邊形內部。如果binarize為 False,則輸出為標記陣列,其中像素的標籤介於 0 到 3 之間。值的意義是:O - 外部,1 - 內部,2 - 頂點,3 - 邊緣。
另請參閱
- skimage.measure.inertia_tensor(image, mu=None, *, spacing=None)[原始碼]#
計算輸入影像的慣性張量。
- 參數:
- image陣列
輸入影像。
- mu陣列,選用
影像的預先計算中心矩。
image的慣性張量計算需要影像的中心矩。如果應用程式同時需要中心矩和慣性張量(例如,skimage.measure.regionprops),則預先計算它們並將它們傳遞給慣性張量呼叫會更有效率。- spacing:浮點數元組,形狀為 (ndim,)
沿影像每個軸的像素間距。
- 傳回:
- T陣列,形狀
(image.ndim, image.ndim) 輸入影像的慣性張量。\(T_{i, j}\) 包含沿著軸 \(i\) 和 \(j\) 的影像強度共變異數。
- T陣列,形狀
參考文獻
[2]Bernd Jähne. Spatio-Temporal Image Processing: Theory and Scientific Applications. (Chapter 8: Tensor Methods) Springer, 1993.
- skimage.measure.inertia_tensor_eigvals(image, mu=None, T=None, *, spacing=None)[原始碼]#
計算影像慣性張量的特徵值。
慣性張量測量影像強度沿影像軸的共變異數。(請參閱
inertia_tensor。)因此,張量的特徵值的相對大小是對影像中(明亮)物體伸長程度的度量。- 參數:
- image陣列
輸入影像。
- mu陣列,選用
image的預先計算的中心動量。- T陣列,形狀
(image.ndim, image.ndim) 預先計算的慣性張量。如果給定
T,則會忽略mu和image。- spacing:浮點數元組,形狀為 (ndim,)
沿影像每個軸的像素間距。
- 傳回:
- eigvals浮點數列表,長度為
image.ndim image的慣性張量的特徵值,依降序排列。
- eigvals浮點數列表,長度為
備註
計算特徵值需要輸入影像的慣性張量。如果提供中心動量(
mu),或者,也可以直接提供慣性張量(T),速度會快得多。
- skimage.measure.intersection_coeff(image0_mask, image1_mask, mask=None)[原始碼]#
一個通道的分割二元遮罩與第二個通道的分割二元遮罩重疊的部分比例。
- 參數:
- image0_mask(M, N) 具有布林資料型態的 ndarray
通道 A 的影像遮罩。
- image1_mask(M, N) 具有布林資料型態的 ndarray
通道 B 的影像遮罩。必須與
image0_mask具有相同的維度。- mask(M, N) 具有布林資料型態的 ndarray,可選
在計算中,僅包含此感興趣區域遮罩內的
image0_mask和image1_mask像素。必須與image0_mask具有相同的維度。
- 傳回:
- 交集係數,浮點數
image0_mask與image1_mask重疊的部分比例。
- skimage.measure.label(label_image, background=None, return_num=False, connectivity=None)[原始碼]#
標記整數陣列的連通區域。
當兩個像素是相鄰且具有相同的值時,它們會被視為連接。在 2D 中,它們可以以 1 連接或 2 連接的方式成為鄰居。該值是指將像素/體素視為鄰居所考慮的正交跳躍最大次數
1-connectivity 2-connectivity diagonal connection close-up [ ] [ ] [ ] [ ] [ ] | \ | / | <- hop 2 [ ]--[x]--[ ] [ ]--[x]--[ ] [x]--[ ] | / | \ hop 1 [ ] [ ] [ ] [ ]
- 參數:
- label_image具有整數資料型態的 ndarray
要標記的影像。
- background整數,可選
將所有具有此值的像素視為背景像素,並將它們標記為 0。預設情況下,值為 0 的像素會被視為背景像素。
- return_num布林值,可選
是否傳回指定的標籤數量。
- connectivityint,選用
將像素/體素視為鄰居所考慮的最大正交跳躍次數。可接受的值範圍為 1 到 input.ndim。如果為
None,則使用input.ndim的完整連通性。
- 傳回:
- labels具有整數資料型態的 ndarray
已標記的陣列,其中所有連接的區域都被分配相同的整數值。
- num整數,可選
標籤的數量,等於最大標籤索引,且僅在 return_num 為
True時傳回。
參考文獻
[1]Christophe Fiorio 和 Jens Gustedt,“用於影像處理的兩種線性時間 Union-Find 策略”,理論計算機科學 154 (1996),第 165-181 頁。
[2]Kensheng Wu、Ekow Otoo 和 Arie Shoshani,“優化連通分量標記演算法”,論文 LBNL-56864, 2005, 勞倫斯伯克利國家實驗室(加州大學),http://repositories.cdlib.org/lbnl/LBNL-56864
範例
>>> import numpy as np >>> x = np.eye(3).astype(int) >>> print(x) [[1 0 0] [0 1 0] [0 0 1]] >>> print(label(x, connectivity=1)) [[1 0 0] [0 2 0] [0 0 3]] >>> print(label(x, connectivity=2)) [[1 0 0] [0 1 0] [0 0 1]] >>> print(label(x, background=-1)) [[1 2 2] [2 1 2] [2 2 1]] >>> x = np.array([[1, 0, 0], ... [1, 1, 5], ... [0, 0, 0]]) >>> print(label(x)) [[1 0 0] [1 1 2] [0 0 0]]



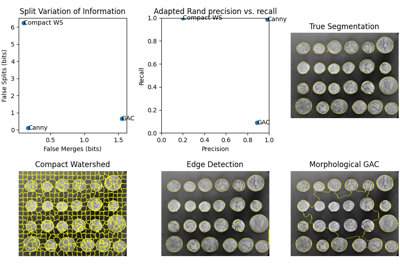
- skimage.measure.manders_coloc_coeff(image0, image1_mask, mask=None)[原始碼]#
兩個通道之間的曼德斯共定位係數。
- 參數:
- image0(M, N) ndarray
通道 A 的影像。所有像素值都應為非負數。
- image1_mask(M, N) 具有布林資料型態的 ndarray
二元遮罩,其中包含通道 B 中感興趣的分割區域。必須與
image0具有相同的維度。- mask(M, N) 具有布林資料型態的 ndarray,可選
在計算中,僅包含此感興趣區域遮罩內的
image0像素值。必須與image0具有相同的維度。
- 傳回:
- mcc浮點數
曼德斯共定位係數。
備註
曼德斯共定位係數 (MCC) 是某個通道(通道 A)的總強度中,位於第二個通道(通道 B)的分割區域內的比例 [1]。其範圍從 0(表示無共定位)到 1(表示完全共定位)。它也被稱為 M1 和 M2。
MCC 通常用於測量亞細胞區室中特定蛋白質的共定位。通常,透過設定一個閾值來產生通道 B 的分割遮罩,像素值必須高於該閾值才能被納入 MCC 計算中。在此實作中,通道 B 遮罩以參數
image1_mask的形式提供,讓使用者可以預先決定確切的分割方法。實作的公式為
\[r = \frac{\sum A_{i,coloc}}{\sum A_i}\]- 其中
\(A_i\) 是
image0中第 \(i^{th}\) 個像素的值 \(A_{i,coloc} = A_i\) 如果 \(Bmask_i > 0\) \(Bmask_i\) 是mask中第 \(i^{th}\) 個像素的值
MCC 對雜訊很敏感,第一個通道中的漫射訊號會膨脹其值。在計算 MCC 之前,應先處理影像以移除失焦和背景光 [2]。
參考文獻
[1]Manders, E.M.M., Verbeek, F.J. 和 Aten, J.A. (1993),雙色共焦影像中物件共定位的測量。顯微鏡學期刊,169: 375-382。 https://doi.org/10.1111/j.1365-2818.1993.tb03313.x https://imagej.net/media/manders.pdf
[2]Dunn, K. W.、Kamocka, M. M. 和 McDonald, J. H. (2011)。生物顯微鏡中評估共定位的實用指南。美國生理學期刊。細胞生理學,300(4), C723–C742。 https://doi.org/10.1152/ajpcell.00462.2010
- skimage.measure.manders_overlap_coeff(image0, image1, mask=None)[原始碼]#
曼德斯重疊係數
- 參數:
- image0(M, N) ndarray
通道 A 的影像。所有像素值都應為非負數。
- image1(M, N) ndarray
B 通道的影像。所有像素值應為非負數。必須與
image0具有相同的維度。- mask(M, N) 具有布林資料型態的 ndarray,可選
計算時僅包含此感興趣區域遮罩內的
image0和image1像素值。必須與image0具有♣相同的維度。
- 傳回:
- moc: float
兩個影像之間像素強度的曼德斯重疊係數 (Manders’ Overlap Coefficient)。
備註
曼德斯重疊係數 (MOC) 由以下方程式給出 [1]
\[r = \frac{\sum A_i B_i}{\sqrt{\sum A_i^2 \sum B_i^2}}\]- 其中
\(A_i\) 是
image0中第 \(i\) 個像素的值,\(B_i\) 是image1中第 \(i\) 個像素的值
其範圍介於 0(表示沒有共定位)和 1(表示所有像素完全共定位)之間。
MOC 不考慮像素強度,只考慮兩個通道都具有正值的像素比例[R2208c1a5d6e1-2]_ [3]。其效用性受到批評,因為它會因共現性和相關性的差異而改變,因此特定的 MOC 值可能表示各種不同的共定位模式 [4] [5]。
參考文獻
[1]Manders, E.M.M., Verbeek, F.J. 和 Aten, J.A. (1993),雙色共焦影像中物件共定位的測量。顯微鏡學期刊,169: 375-382。 https://doi.org/10.1111/j.1365-2818.1993.tb03313.x https://imagej.net/media/manders.pdf
[2]Dunn, K. W.、Kamocka, M. M. 和 McDonald, J. H. (2011)。生物顯微鏡中評估共定位的實用指南。美國生理學期刊。細胞生理學,300(4), C723–C742。 https://doi.org/10.1152/ajpcell.00462.2010
[3]Bolte, S. 和 Cordelières, F.P. (2006), A guided tour into subcellular colocalization analysis in light microscopy. Journal of Microscopy, 224: 213-232. https://doi.org/10.1111/j.1365-2818.2006.01
[4]Adler J, Parmryd I. (2010), Quantifying colocalization by correlation: the Pearson correlation coefficient is superior to the Mander’s overlap coefficient. Cytometry A. Aug;77(8):733-42.https://doi.org/10.1002/cyto.a.20896
[5]Adler, J, Parmryd, I. Quantifying colocalization: The case for discarding the Manders overlap coefficient. Cytometry. 2021; 99: 910– 920. https://doi.org/10.1002/cyto.a.24336
- skimage.measure.marching_cubes(volume, level=None, *, spacing=(1.0, 1.0, 1.0), gradient_direction='descent', step_size=1, allow_degenerate=True, method='lewiner', mask=None)[source]#
用於尋找 3D 體積資料中表面的行進立方體演算法。
與 Lorensen 等人的方法 [2] 相比,Lewiner 等人的演算法速度更快、可解決歧義,並保證拓樸正確的結果。因此,此演算法通常是更好的選擇。
- 參數:
- volume(M, N, P) ndarray
用於尋找等值面的輸入資料體積。如有必要,將在內部轉換為 float32。
- levelfloat,選用
在
volume中搜尋等值面的輪廓值。如果未給定或為 None,則使用 vol 的最小值和最大值的平均值。- spacing長度為 3 的浮點數元組,選用
空間維度中的體素間距,對應於 numpy 陣列索引維度 (M, N, P),如
volume中所示。- gradient_direction字串,選用
控制網格是從朝向感興趣物件的梯度下降(預設值)的等值面產生,還是從相反的方向產生,考慮「左手定則」。兩個選項是:* descent:物件大於外部 * ascent:外部大於物件
- step_size整數,選用
體素中的步長。預設值為 1。較大的步長會產生更快但較粗糙的結果。但結果始終在拓樸上是正確的。
- allow_degenerate布林值,選用
是否允許最終結果中出現退化(即零面積)三角形。預設值為 True。如果為 False,則會移除退化三角形,但會使演算法速度變慢。
- method: {‘lewiner’, ‘lorensen’}, 選用
將使用 Lewiner 等人或 Lorensen 等人的方法。
- mask(M, N, P) 陣列,選用
布林值陣列。行進立方體演算法僅會對 True 元素計算。當介面位於體積 M、N、P 的特定區域內(例如,立方體的上半部)時,這會節省計算時間,並且還可以計算有限的曲面(即,不以立方體邊界結束的開放曲面)。
- 傳回:
- verts(V, 3) 陣列
V 個唯一網格頂點的空間座標。座標順序符合輸入
volume(M, N, P)。如果allow_degenerate設定為 True,則網格中存在退化三角形會導致此陣列具有重複的頂點。- faces(F, 3) 陣列
透過從
verts參照頂點索引來定義三角形面。此演算法特別輸出三角形,因此每個面都有三個索引。- normals(V, 3) 陣列
根據資料計算出的每個頂點的法線方向。
- values(V,) 陣列
提供每個頂點附近局部區域中資料最大值的度量。視覺化工具可以使用此值將色彩圖套用至網格。
備註
演算法 [1] 是 Chernyaev 的行進立方體 33 演算法的改進版本。它是一種有效率的演算法,大量依賴查找表來處理許多不同的情況,使演算法相對容易。此實作是用 Cython 編寫的,從 Lewiner 的 C++ 實作移植而來。
若要量化由此演算法產生的等值面的面積,請將 verts 和 faces 傳遞給
skimage.measure.mesh_surface_area。關於演算法輸出的視覺化,若要使用
mayavi套件,將名為myvolume的體積繪製輪廓於 0.0 的等級>>> >> from mayavi import mlab >> verts, faces, _, _ = marching_cubes(myvolume, 0.0) >> mlab.triangular_mesh([vert[0] for vert in verts], [vert[1] for vert in verts], [vert[2] for vert in verts], faces) >> mlab.show()
同樣使用
visvis套件>>> >> import visvis as vv >> verts, faces, normals, values = marching_cubes(myvolume, 0.0) >> vv.mesh(np.fliplr(verts), faces, normals, values) >> vv.use().Run()
若要減少網格中的三角形數量以獲得更好的效能,請參閱此範例,其中使用
mayavi套件。參考文獻
[1]Thomas Lewiner、Helio Lopes、Antonio Wilson Vieira 和 Geovan Tavares。Efficient implementation of Marching Cubes’ cases with topological guarantees. Journal of Graphics Tools 8(2) pp. 1-15 (december 2003)。DOI:10.1080/10867651.2003.10487582
[2]Lorensen, William and Harvey E. Cline. Marching Cubes: A High Resolution 3D Surface Construction Algorithm. Computer Graphics (SIGGRAPH 87 Proceedings) 21(4) July 1987, p. 163-170). DOI:10.1145/37401.37422
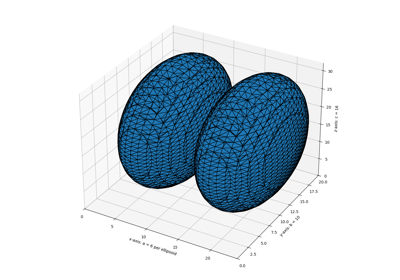
- skimage.measure.mesh_surface_area(verts, faces)[source]#
計算給定頂點和三角形面的表面積。
- 參數:
- verts(V, 3) 浮點數陣列
包含 V 個唯一網格頂點座標的陣列。
- faces(F, 3) 整數陣列
長度為 3 的整數列表,參考
verts中提供的頂點座標。
- 傳回:
- area浮點數
網格的表面積。單位現在是 [座標單位] ** 2。
備註
此函數預期的引數是
skimage.measure.marching_cubes的前兩個輸出。若要取得單位正確的輸出,請確保將正確的spacing傳遞至skimage.measure.marching_cubes。僅當提供的
faces全都是三角形時,此演算法才能正常運作。
- skimage.measure.moments(image, order=3, *, spacing=None)[source]#
計算直到特定階數的所有原始影像矩。
- 可以從原始影像矩計算以下屬性
面積為:
M[0, 0]。質心為:{
M[1, 0] / M[0, 0]、M[0, 1] / M[0, 0]}。
請注意,原始矩既不是平移、縮放也不是旋轉不變量。
- 參數:
- image(N[, …]) 雙精度或 uint8 陣列
以影像形式呈現的柵格化形狀。
- order整數,選用
矩的最大階數。預設值為 3。
- spacing:浮點數元組,形狀為 (ndim,)
沿影像每個軸的像素間距。
- 傳回:
- m(
order + 1、order + 1) 陣列 原始影像矩。
- m(
參考文獻
[1]Wilhelm Burger、Mark Burge。Principles of Digital Image Processing: Core Algorithms。Springer-Verlag,倫敦,2009 年。
[2]B. Jähne。Digital Image Processing。Springer-Verlag,柏林-海德堡,第 6 版,2005 年。
[3]T. H. Reiss。Recognizing Planar Objects Using Invariant Image Features,取自電腦科學講義,第 676 頁。Springer,柏林,1993 年。
範例
>>> image = np.zeros((20, 20), dtype=np.float64) >>> image[13:17, 13:17] = 1 >>> M = moments(image) >>> centroid = (M[1, 0] / M[0, 0], M[0, 1] / M[0, 0]) >>> centroid (14.5, 14.5)
- skimage.measure.moments_central(image, center=None, order=3, *, spacing=None, **kwargs)[原始碼]#
計算直到特定階數的所有中心影像矩。
中心座標 (cr, cc) 可以從原始矩計算得出:{
M[1, 0] / M[0, 0],M[0, 1] / M[0, 0]}。請注意,中心矩具有平移不變性,但不具備縮放和旋轉不變性。
- 參數:
- image(N[, …]) 雙精度或 uint8 陣列
以影像形式呈現的柵格化形狀。
- centertuple of float, optional
影像質心的座標。如果未提供,則會計算此值。
- order整數,選用
計算的矩的最大階數。
- spacing:浮點數元組,形狀為 (ndim,)
沿影像每個軸的像素間距。
- 傳回:
- mu(
order + 1,order + 1) 陣列 中心影像矩。
- mu(
參考文獻
[1]Wilhelm Burger、Mark Burge。Principles of Digital Image Processing: Core Algorithms。Springer-Verlag,倫敦,2009 年。
[2]B. Jähne。Digital Image Processing。Springer-Verlag,柏林-海德堡,第 6 版,2005 年。
[3]T. H. Reiss。Recognizing Planar Objects Using Invariant Image Features,取自電腦科學講義,第 676 頁。Springer,柏林,1993 年。
範例
>>> image = np.zeros((20, 20), dtype=np.float64) >>> image[13:17, 13:17] = 1 >>> M = moments(image) >>> centroid = (M[1, 0] / M[0, 0], M[0, 1] / M[0, 0]) >>> moments_central(image, centroid) array([[16., 0., 20., 0.], [ 0., 0., 0., 0.], [20., 0., 25., 0.], [ 0., 0., 0., 0.]])
- skimage.measure.moments_coords(coords, order=3)[原始碼]#
計算直到特定階數的所有原始影像矩。
- 可以從原始影像矩計算以下屬性
面積為:
M[0, 0]。質心為:{
M[1, 0] / M[0, 0]、M[0, 1] / M[0, 0]}。
請注意,原始矩不具備平移、縮放或旋轉不變性。
- 參數:
- coords(N, D) double 或 uint8 陣列
描述笛卡爾空間中 D 維影像的 N 個點的陣列。
- order整數,選用
矩的最大階數。預設值為 3。
- 傳回:
- M(
order + 1,order + 1, …) 陣列 原始影像矩。(D 維)
- M(
參考文獻
[1]Johannes Kilian. Simple Image Analysis By Moments. Durham University, version 0.2, Durham, 2001.
範例
>>> coords = np.array([[row, col] ... for row in range(13, 17) ... for col in range(14, 18)], dtype=np.float64) >>> M = moments_coords(coords) >>> centroid = (M[1, 0] / M[0, 0], M[0, 1] / M[0, 0]) >>> centroid (14.5, 15.5)
- skimage.measure.moments_coords_central(coords, center=None, order=3)[原始碼]#
計算直到特定階數的所有中心影像矩。
- 可以從原始影像矩計算以下屬性
面積為:
M[0, 0]。質心為:{
M[1, 0] / M[0, 0]、M[0, 1] / M[0, 0]}。
請注意,原始矩既不是平移、縮放也不是旋轉不變量。
- 參數:
- coords(N, D) double 或 uint8 陣列
描述笛卡爾空間中 D 維影像的 N 個點的陣列。也可以接受
np.nonzero返回的座標 tuple 作為輸入。- centertuple of float, optional
影像質心的座標。如果未提供,則會計算此值。
- order整數,選用
矩的最大階數。預設值為 3。
- 傳回:
- Mc(
order + 1,order + 1, …) 陣列 中心影像矩。(D 維)
- Mc(
參考文獻
[1]Johannes Kilian. Simple Image Analysis By Moments. Durham University, version 0.2, Durham, 2001.
範例
>>> coords = np.array([[row, col] ... for row in range(13, 17) ... for col in range(14, 18)]) >>> moments_coords_central(coords) array([[16., 0., 20., 0.], [ 0., 0., 0., 0.], [20., 0., 25., 0.], [ 0., 0., 0., 0.]])
如上所示,對於對稱物件,當以物件的質心(或質量中心)為中心時(預設值),奇數階矩(第 1 和第 3 行,第 1 和第 3 列)為零。如果我們透過新增一個新點來打破對稱性,則不再成立。
>>> coords2 = np.concatenate((coords, [[17, 17]]), axis=0) >>> np.round(moments_coords_central(coords2), ... decimals=2) array([[17. , 0. , 22.12, -2.49], [ 0. , 3.53, 1.73, 7.4 ], [25.88, 6.02, 36.63, 8.83], [ 4.15, 19.17, 14.8 , 39.6 ]])
當中心為 (0, 0) 時,影像矩和中心影像矩是等效的(根據定義)。
>>> np.allclose(moments_coords(coords), ... moments_coords_central(coords, (0, 0))) True
- skimage.measure.moments_hu(nu)[原始碼]#
計算 Hu 的影像矩集合(僅限 2D)。
請注意,這組矩已被證明具有平移、縮放和旋轉不變性。
- 參數:
- nu(M, M) 陣列
標準化的中心影像矩,其中 M 必須 >= 4。
- 傳回:
- nu(7,) 陣列
Hu 的影像矩集合。
參考文獻
[1]M. K. Hu, “Visual Pattern Recognition by Moment Invariants”, IRE Trans. Info. Theory, vol. IT-8, pp. 179-187, 1962
[2]Wilhelm Burger、Mark Burge。Principles of Digital Image Processing: Core Algorithms。Springer-Verlag,倫敦,2009 年。
[3]B. Jähne。Digital Image Processing。Springer-Verlag,柏林-海德堡,第 6 版,2005 年。
[4]T. H. Reiss。Recognizing Planar Objects Using Invariant Image Features,取自電腦科學講義,第 676 頁。Springer,柏林,1993 年。
範例
>>> image = np.zeros((20, 20), dtype=np.float64) >>> image[13:17, 13:17] = 0.5 >>> image[10:12, 10:12] = 1 >>> mu = moments_central(image) >>> nu = moments_normalized(mu) >>> moments_hu(nu) array([0.74537037, 0.35116598, 0.10404918, 0.04064421, 0.00264312, 0.02408546, 0. ])
- skimage.measure.moments_normalized(mu, order=3, spacing=None)[原始碼]#
計算直到特定階數的所有標準化中心影像矩。
請注意,標準化的中心矩具有平移和縮放不變性,但不具備旋轉不變性。
- 參數:
- mu(M[, …], M) 陣列
中心影像矩,其中 M 必須大於或等於
order。- order整數,選用
矩的最大階數。預設值為 3。
- spacing:浮點數元組,形狀為 (ndim,)
沿影像每個軸的像素間距。
- 傳回:
- nu(
order + 1``[, ...], ``order + 1) 陣列 標準化的中心影像矩。
- nu(
參考文獻
[1]Wilhelm Burger、Mark Burge。Principles of Digital Image Processing: Core Algorithms。Springer-Verlag,倫敦,2009 年。
[2]B. Jähne。Digital Image Processing。Springer-Verlag,柏林-海德堡,第 6 版,2005 年。
[3]T. H. Reiss。Recognizing Planar Objects Using Invariant Image Features,取自電腦科學講義,第 676 頁。Springer,柏林,1993 年。
範例
>>> image = np.zeros((20, 20), dtype=np.float64) >>> image[13:17, 13:17] = 1 >>> m = moments(image) >>> centroid = (m[0, 1] / m[0, 0], m[1, 0] / m[0, 0]) >>> mu = moments_central(image, centroid) >>> moments_normalized(mu) array([[ nan, nan, 0.078125 , 0. ], [ nan, 0. , 0. , 0. ], [0.078125 , 0. , 0.00610352, 0. ], [0. , 0. , 0. , 0. ]])
- skimage.measure.pearson_corr_coeff(image0, image1, mask=None)[原始碼]#
計算通道中像素強度之間的皮爾森相關係數。
- 參數:
- image0(M, N) ndarray
通道 A 的影像。
- image1(M, N) ndarray
要與通道 B 相關聯的通道 2 的影像。必須具有與
image0相同的維度。- mask(M, N) 具有布林資料型態的 ndarray,可選
僅當
image0和image1像素位於此感興趣區域遮罩內時,才會將它們包含在計算中。必須具有與image0相同的維度。
- 傳回:
- pccfloat
兩個影像之間像素強度的皮爾森相關係數,如果提供遮罩,則在遮罩內計算。
- p-valuefloat
雙尾 p 值。
備註
皮爾森相關係數 (PCC) 測量兩個影像的像素強度之間的線性相關性。其值範圍從 -1(完美線性反相關)到 +1(完美線性相關)。p 值的計算假設每個輸入影像中的像素強度均為常態分佈。
使用 Scipy 的皮爾森相關係數實作。有關更多資訊和注意事項,請參閱它[1]。
\[r = \frac{\sum (A_i - m_A_i) (B_i - m_B_i)} {\sqrt{\sum (A_i - m_A_i)^2 \sum (B_i - m_B_i)^2}}\]- 其中
\(A_i\) 是
image0中第 \(i^{th}\) 個像素的值,\(B_i\) 是image1中第 \(i^{th}\) 個像素的值,\(m_A_i\) 是image0中像素值的平均值,\(m_B_i\) 是image1中像素值的平均值
較低的 PCC 值不一定表示兩個通道強度之間沒有相關性,僅表示沒有線性相關性。您可能希望在 2D 散佈圖中繪製兩個通道的像素強度,如果視覺上識別出非線性相關性,則使用 Spearman 的等級相關性 [2]。另外,請考慮您是否對相關性或共存感興趣,在這種情況下,使用分割遮罩的方法(例如 MCC 或交集係數)可能更適合 [3] [4]。
提供影像的相關部分(例如,細胞或特定的細胞區室)的遮罩並去除雜訊非常重要,因為 PCC 對這些測量非常敏感 [3] [4]。
參考文獻
[3] (1,2)Dunn, K. W.、Kamocka, M. M. 和 McDonald, J. H. (2011)。生物顯微鏡中評估共定位的實用指南。美國生理學期刊。細胞生理學,300(4), C723–C742。 https://doi.org/10.1152/ajpcell.00462.2010
[4] (1,2)Bolte, S. 和 Cordelières, F.P. (2006), A guided tour into subcellular colocalization analysis in light microscopy. Journal of Microscopy, 224: 213-232. https://doi.org/10.1111/j.1365-2818.2006.01706.x
- skimage.measure.perimeter(image, neighborhood=4)[原始碼]#
計算二值影像中所有物件的總周長。
- 參數:
- image(M, N) ndarray
二元輸入影像。
- neighborhood4 或 8,optional
用於邊界像素確定的鄰域連通性。它用於計算輪廓。較高的鄰域會加寬計算周長的邊界。
- 傳回:
- perimeterfloat
二元影像中所有物件的總周長。
參考文獻
[1]K. Benkrid, D. Crookes. Design and FPGA Implementation of a Perimeter Estimator. The Queen’s University of Belfast. http://www.cs.qub.ac.uk/~d.crookes/webpubs/papers/perimeter.doc
範例
>>> from skimage import data, util >>> from skimage.measure import label >>> # coins image (binary) >>> img_coins = data.coins() > 110 >>> # total perimeter of all objects in the image >>> perimeter(img_coins, neighborhood=4) 7796.867... >>> perimeter(img_coins, neighborhood=8) 8806.268...
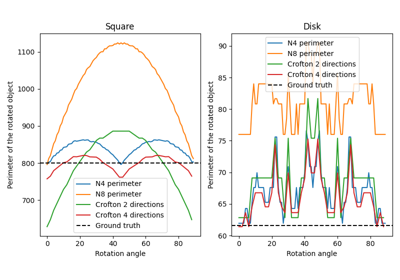
- skimage.measure.perimeter_crofton(image, directions=4)[原始碼]#
計算二值影像中所有物件的總克羅夫頓周長。
- 參數:
- image(M, N) ndarray
輸入影像。 如果影像不是二值的,則大於零的所有值都視為物件。
- directions2 或 4,optional
用於近似 Crofton 周長的方向數。預設情況下,使用 4:它應該比 2 更準確。兩種情況下的計算時間相同。
- 傳回:
- perimeterfloat
二元影像中所有物件的總周長。
備註
此度量基於 Crofton 公式 [1],該公式是積分幾何中的一種度量。它被定義為通過沿所有方向的雙重積分來評估一般曲線的長度。在離散空間中,2 或 4 個方向可以提供相當好的近似值,對於更複雜的形狀,4 個方向比 2 個方向更準確。
與
perimeter()類似,此函數返回連續空間中周長的近似值。參考文獻
[2]S. Rivollier. Analyse d’image geometrique et morphometrique par diagrammes de forme et voisinages adaptatifs generaux. PhD thesis, 2010. Ecole Nationale Superieure des Mines de Saint-Etienne. https://tel.archives-ouvertes.fr/tel-00560838
範例
>>> from skimage import data, util >>> from skimage.measure import label >>> # coins image (binary) >>> img_coins = data.coins() > 110 >>> # total perimeter of all objects in the image >>> perimeter_crofton(img_coins, directions=2) 8144.578... >>> perimeter_crofton(img_coins, directions=4) 7837.077...
- skimage.measure.points_in_poly(points, verts)[原始碼]#
測試點是否位於多邊形內。
- 參數:
- points(K, 2) 陣列
輸入點,
(x, y)。- verts(L, 2) 陣列
多邊形的頂點,依順時針或逆時針排序。第一個點可以(但不一定需要)重複。
- 傳回:
- mask(K,) 布林陣列
如果對應的點在多邊形內,則為 True。
另請參閱
- skimage.measure.profile_line(image, src, dst, linewidth=1, order=None, mode='reflect', cval=0.0, *, reduce_func=<function mean>)[原始碼]#
傳回沿掃描線測量的影像強度輪廓。
- 參數:
- imagendarray,形狀 (M, N[, C])
影像,可以是灰階 (2D 陣列) 或多通道 (3D 陣列,其中最後一個軸包含通道資訊)。
- srcarray_like,形狀 (2,)
掃描線起點的座標。
- dstarray_like,形狀 (2,)
掃描線終點的座標。與標準 numpy 索引相反,終點包含在輪廓中。
- linewidthint,可選
掃描寬度,垂直於線條。
- orderint,在 {0, 1, 2, 3, 4, 5} 中,可選
樣條內插的階數,如果 image.dtype 是布林值則預設為 0,否則為 1。階數必須在 0-5 的範圍內。詳情請參閱
skimage.transform.warp。- mode{'constant','nearest','reflect','mirror','wrap'},可選
如何計算影像外部的任何值。
- cvalfloat,可選
如果
mode為 'constant',則在影像外部使用什麼常數值。- reduce_func可呼叫,選用
當
linewidth> 1 時,用於計算垂直於 profile_line 方向的像素值聚合的函數。如果設定為 None,則會傳回未縮減的陣列。
- 傳回:
- return_value陣列
沿掃描線的強度輪廓。輪廓的長度是掃描線計算長度的上限。
範例
>>> x = np.array([[1, 1, 1, 2, 2, 2]]) >>> img = np.vstack([np.zeros_like(x), x, x, x, np.zeros_like(x)]) >>> img array([[0, 0, 0, 0, 0, 0], [1, 1, 1, 2, 2, 2], [1, 1, 1, 2, 2, 2], [1, 1, 1, 2, 2, 2], [0, 0, 0, 0, 0, 0]]) >>> profile_line(img, (2, 1), (2, 4)) array([1., 1., 2., 2.]) >>> profile_line(img, (1, 0), (1, 6), cval=4) array([1., 1., 1., 2., 2., 2., 2.])
與標準 numpy 索引相反,終點包含在輪廓中。例如
>>> profile_line(img, (1, 0), (1, 6)) # The final point is out of bounds array([1., 1., 1., 2., 2., 2., 2.]) >>> profile_line(img, (1, 0), (1, 5)) # This accesses the full first row array([1., 1., 1., 2., 2., 2.])
對於不同的 reduce_func 輸入
>>> profile_line(img, (1, 0), (1, 3), linewidth=3, reduce_func=np.mean) array([0.66666667, 0.66666667, 0.66666667, 1.33333333]) >>> profile_line(img, (1, 0), (1, 3), linewidth=3, reduce_func=np.max) array([1, 1, 1, 2]) >>> profile_line(img, (1, 0), (1, 3), linewidth=3, reduce_func=np.sum) array([2, 2, 2, 4])
當
reduce_func為 None 或當reduce_func單獨作用於每個像素值時,會傳回未縮減的陣列。>>> profile_line(img, (1, 2), (4, 2), linewidth=3, order=0, ... reduce_func=None) array([[1, 1, 2], [1, 1, 2], [1, 1, 2], [0, 0, 0]]) >>> profile_line(img, (1, 0), (1, 3), linewidth=3, reduce_func=np.sqrt) array([[1. , 1. , 0. ], [1. , 1. , 0. ], [1. , 1. , 0. ], [1.41421356, 1.41421356, 0. ]])
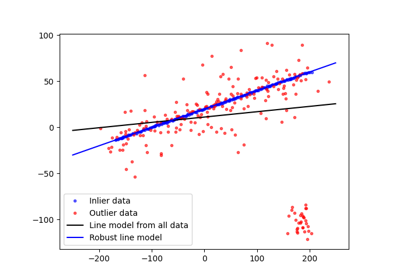
- skimage.measure.ransac(data, model_class, min_samples, residual_threshold, is_data_valid=None, is_model_valid=None, max_trials=100, stop_sample_num=inf, stop_residuals_sum=0, stop_probability=1, rng=None, initial_inliers=None)[原始碼]#
使用 RANSAC(隨機樣本共識)演算法將模型擬合到資料。
RANSAC 是一種迭代演算法,用於從完整資料集中內點的子集穩健地估計參數。每次迭代都會執行以下任務
從原始資料中選取
min_samples個隨機樣本,並檢查資料集是否有效(請參閱is_data_valid)。估計隨機子集的模型 (
model_cls.estimate(*data[random_subset]),並檢查估計的模型是否有效(請參閱is_model_valid)。透過計算估計模型的殘差 (
model_cls.residuals(*data)) 將所有資料分類為內點或離群值 - 所有殘差小於residual_threshold的資料樣本都被視為內點。如果內點樣本數量最大,則將估計的模型儲存為最佳模型。如果目前估計的模型具有相同數量的內點,則只有在它具有較小的殘差總和時,才會被視為最佳模型。
這些步驟會執行最大次數,或直到滿足其中一個特殊的停止條件。最後的模型是使用先前確定的最佳模型的所有內點樣本進行估計。
- 參數:
- data[list,tuple of] (N, …) 陣列
要將模型擬合到的資料集,其中 N 是資料點的數量,其餘維度取決於模型要求。如果模型類別需要多個輸入資料陣列 (例如,
skimage.transform.AffineTransform的來源和目標座標),則可以選擇將它們作為 tuple 或 list 傳遞。請注意,在這種情況下,函數estimate(*data)、residuals(*data)、is_model_valid(model, *random_data)和is_data_valid(*random_data)都必須將每個資料陣列作為單獨的引數。- model_class物件
具有以下物件方法的物件
success = estimate(*data)residuals(*data)
- min_samplesint,範圍 (0, N)
要擬合模型的最小資料點數。
- residual_thresholdfloat,大於 0
資料點被分類為內點的最大距離。
- is_data_valid函數,可選
此函數在將模型擬合到隨機選取的資料之前,會使用隨機選取的資料來呼叫:
is_data_valid(*random_data)。- is_model_valid函數,可選
此函數會使用估計的模型和隨機選取的資料來呼叫:
is_model_valid(model, *random_data)。- max_trialsint,可選
隨機樣本選取的最大迭代次數。
- stop_sample_numint,可選
如果找到至少這個數量的內點,則停止迭代。
- stop_residuals_sumfloat,可選
如果殘差總和小於或等於此閾值,則停止迭代。
- stop_probabilityfloat,範圍 [0, 1],可選
如果至少有一個無離群值的訓練資料集採樣的
probability >= stop_probability,則 RANSAC 迭代會停止,這取決於目前最佳模型的內點比率和試驗次數。這需要產生至少 N 個樣本(試驗)N >= log(1 - probability) / log(1 - e**m)
其中機率(信賴度)通常設定為較高的值,例如 0.99,e 是目前內點相對於樣本總數的比例,而 m 是 min_samples 值。
- rng{
numpy.random.Generator, int},可選 虛擬亂數產生器。預設情況下,會使用 PCG64 產生器(請參閱
numpy.random.default_rng())。如果rng是 int,則會用來為產生器設定種子。- initial_inliers類陣列布林值,形狀 (N,),可選
用於模型估計的初始樣本選取
- 傳回:
- model物件
具有最大共識集的最佳模型。
- inliers(N,) 陣列
分類為
True的內點布林遮罩。
參考文獻
[1]“RANSAC”,維基百科,https://en.wikipedia.org/wiki/RANSAC
範例
產生沒有傾斜並新增雜訊的橢圓資料
>>> t = np.linspace(0, 2 * np.pi, 50) >>> xc, yc = 20, 30 >>> a, b = 5, 10 >>> x = xc + a * np.cos(t) >>> y = yc + b * np.sin(t) >>> data = np.column_stack([x, y]) >>> rng = np.random.default_rng(203560) # do not copy this value >>> data += rng.normal(size=data.shape)
新增一些錯誤的資料
>>> data[0] = (100, 100) >>> data[1] = (110, 120) >>> data[2] = (120, 130) >>> data[3] = (140, 130)
使用所有可用資料估計橢圓模型
>>> model = EllipseModel() >>> model.estimate(data) True >>> np.round(model.params) array([ 72., 75., 77., 14., 1.])
使用 RANSAC 估計橢圓模型
>>> ransac_model, inliers = ransac(data, EllipseModel, 20, 3, max_trials=50) >>> abs(np.round(ransac_model.params)) array([20., 30., 10., 6., 2.]) >>> inliers array([False, False, False, False, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True], dtype=bool) >>> sum(inliers) > 40 True
RANSAC 可用於穩健地估計幾何變換。在本節中,我們也展示如何使用總樣本的比例,而不是絕對數字。
>>> from skimage.transform import SimilarityTransform >>> rng = np.random.default_rng() >>> src = 100 * rng.random((50, 2)) >>> model0 = SimilarityTransform(scale=0.5, rotation=1, ... translation=(10, 20)) >>> dst = model0(src) >>> dst[0] = (10000, 10000) >>> dst[1] = (-100, 100) >>> dst[2] = (50, 50) >>> ratio = 0.5 # use half of the samples >>> min_samples = int(ratio * len(src)) >>> model, inliers = ransac( ... (src, dst), ... SimilarityTransform, ... min_samples, ... 10, ... initial_inliers=np.ones(len(src), dtype=bool), ... ) >>> inliers array([False, False, False, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True])
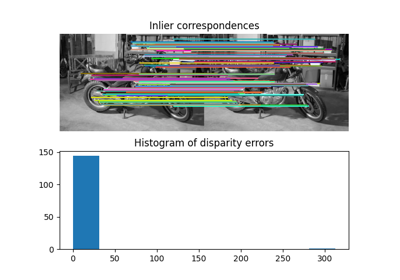


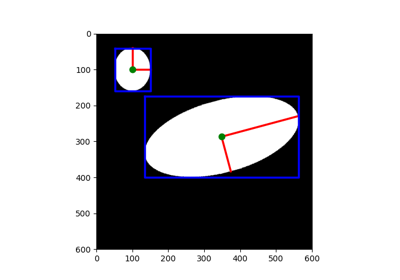
- skimage.measure.regionprops(label_image, intensity_image=None, cache=True, *, extra_properties=None, spacing=None, offset=None)[原始碼]#
測量標記影像區域的屬性。
- 參數:
- label_image(M, N[, P]) ndarray
已標記的輸入影像。數值為 0 的標籤會被忽略。
變更於 0.14.1 版本: 先前,
label_image由numpy.squeeze處理,因此允許任意數量的單例維度。這導致對具有單例維度的影像處理不一致。要恢復舊行為,請使用regionprops(np.squeeze(label_image), ...)。- intensity_image(M, N[, P][, C]) ndarray,可選
強度(即輸入)影像,其大小與已標記的影像相同,並且可選地具有用於多通道數據的額外維度。目前,如果存在這個額外通道維度,則它必須是最後一個軸。預設值為 None。
變更於 0.18.0 版本: 新增了提供通道額外維度的功能。
- cachebool,可選
決定是否快取計算的屬性。對於快取的屬性,計算速度會快得多,但記憶體消耗會增加。
- extra_properties可迭代的呼叫物件
新增額外的屬性計算函數,這些函數不包含在 skimage 中。屬性的名稱來自函數名稱,dtype 是透過對小樣本呼叫函數來推斷的。如果額外屬性的名稱與現有屬性的名稱衝突,則額外屬性將不可見,並發出 UserWarning。屬性計算函數必須將區域遮罩作為其第一個引數。如果屬性需要強度影像,則必須接受強度影像作為第二個引數。
- spacing:浮點數元組,形狀為 (ndim,)
沿影像每個軸的像素間距。
- offset類陣列的整數,形狀為
(label_image.ndim,),可選 標籤影像原點(「左上角」)的座標。通常這是 ([0, ]0, 0),但如果想獲得較大體積內子體積的 regionprops,則可能會有所不同。
- 傳回:
- propertiesRegionProperties 的列表
每個項目都描述一個已標記的區域,並且可以使用下面列出的屬性來存取。
另請參閱
備註
以下屬性可以作為屬性或鍵值存取
- area浮點數
區域的面積,即區域的像素數乘以像素面積。
- area_bboxfloat
邊界框的面積,即邊界框的像素數乘以像素面積。
- area_convexfloat
凸包影像的面積,它是包圍區域的最小凸多邊形。
- area_filledfloat
所有孔洞都填滿的區域面積。
- axis_major_lengthfloat
與區域具有相同正規化二階中心矩的橢圓的長軸長度。
- axis_minor_lengthfloat
與區域具有相同正規化二階中心矩的橢圓的短軸長度。
- bboxtuple
邊界框
(min_row, min_col, max_row, max_col)。屬於邊界框的像素位於半開區間[min_row; max_row)和[min_col; max_col)中。- centroidarray
質心座標元組
(row, col)。- centroid_localarray
質心座標元組
(row, col),相對於區域邊界框。- centroid_weightedarray
質心座標元組
(row, col),使用強度影像加權。- centroid_weighted_localarray
質心座標元組
(row, col),相對於區域邊界框,使用強度影像加權。- coords_scaled(K, 2) ndarray
區域的座標列表
(row, col),按spacing縮放。- coords(K, 2) ndarray
區域的座標列表
(row, col)。- eccentricityfloat
與區域具有相同二階矩的橢圓的離心率。離心率是焦距(焦點之間的距離)與長軸長度的比率。該值位於區間 [0, 1) 中。當它為 0 時,橢圓會變成一個圓。
- equivalent_diameter_areafloat
與區域面積相同的圓的直徑。
- euler_numberint
非零像素集的歐拉特性。計算為連通元件的數量減去孔洞的數量(input.ndim 連通性)。在 3D 中,連通元件的數量加上孔洞的數量減去隧道數量。
- extentfloat
區域中的像素與總邊界框中的像素之比。計算為
area / (rows * cols)- feret_diameter_maxfloat
最大 Feret 直徑,計算為區域凸包輪廓周圍點之間的最長距離,由
find_contours確定。[5]- image(H, J) ndarray
切片的二元區域影像,其大小與邊界框相同。
- image_convex(H, J) ndarray
二元凸包影像,其大小與邊界框相同。
- image_filled(H, J) ndarray
具有填滿孔洞的二元區域影像,其大小與邊界框相同。
- image_intensityndarray
區域邊界框內的影像。
- inertia_tensorndarray
區域繞其質量的慣性張量。
- inertia_tensor_eigvalstuple
慣性張量的特徵值,按遞減順序排列。
- intensity_maxfloat
區域中具有最大強度的值。
- intensity_meanfloat
區域中具有平均強度的值。
- intensity_minfloat
區域中具有最小強度的值。
- intensity_stdfloat
區域中強度的標準差。
- labelint
已標記輸入影像中的標籤。
- moments(3, 3) ndarray
高達三階的空間矩
m_ij = sum{ array(row, col) * row^i * col^j }
其中總和是對區域的
row、col座標進行的。- moments_central(3, 3) ndarray
高達三階的中心矩(平移不變)
mu_ij = sum{ array(row, col) * (row - row_c)^i * (col - col_c)^j }
其中總和是對區域的
row、col座標進行的,而row_c和col_c是區域質心的座標。- moments_hutuple
Hu 矩(平移、縮放和旋轉不變)。
- moments_normalized(3, 3) ndarray
高達三階的正規化矩(平移和縮放不變)
nu_ij = mu_ij / m_00^[(i+j)/2 + 1]
其中
m_00是第零空間矩。- moments_weighted(3, 3) ndarray
高達三階的強度影像的空間矩
wm_ij = sum{ array(row, col) * row^i * col^j }
其中總和是對區域的
row、col座標進行的。- moments_weighted_central(3, 3) ndarray
高達三階的強度影像的中心矩(平移不變)
wmu_ij = sum{ array(row, col) * (row - row_c)^i * (col - col_c)^j }
其中總和是對區域的
row、col座標進行的,而row_c和col_c是區域加權質心的座標。- moments_weighted_hutuple
強度影像的 Hu 矩(平移、縮放和旋轉不變)。
- moments_weighted_normalized(3, 3) ndarray
高達三階的強度影像的正規化矩(平移和縮放不變)
wnu_ij = wmu_ij / wm_00^[(i+j)/2 + 1]
其中
wm_00是第零階空間矩(強度加權面積)。- num_pixelsint
前景像素的數量。
- orientationfloat
第 0 軸(列)與具有與該區域相同二階矩的橢圓之主軸之間的角度,範圍從
-pi/2到pi/2逆時針方向。- perimeterfloat
物件的周長,使用 4 連通性將輪廓近似為通過邊界像素中心的線。
- perimeter_croftonfloat
使用 4 個方向的 Crofton 公式近似的物件周長。
- slice切片元組
從來源影像中提取物件的切片。
- solidityfloat
區域中像素與凸包影像像素的比率。
每個區域也支援迭代,因此您可以執行
for prop in region: print(prop, region[prop])
參考文獻
[1]Wilhelm Burger、Mark Burge。Principles of Digital Image Processing: Core Algorithms。Springer-Verlag,倫敦,2009 年。
[2]B. Jähne。Digital Image Processing。Springer-Verlag,柏林-海德堡,第 6 版,2005 年。
[3]T. H. Reiss。Recognizing Planar Objects Using Invariant Image Features,取自電腦科學講義,第 676 頁。Springer,柏林,1993 年。
[5]W. Pabst, E. Gregorová。顆粒和顆粒系統的特性,第 27-28 頁。ICT 布拉格,2007 年。 https://old.vscht.cz/sil/keramika/Characterization_of_particles/CPPS%20_English%20version_.pdf
範例
>>> from skimage import data, util >>> from skimage.measure import label, regionprops >>> img = util.img_as_ubyte(data.coins()) > 110 >>> label_img = label(img, connectivity=img.ndim) >>> props = regionprops(label_img) >>> # centroid of first labeled object >>> props[0].centroid (22.72987986048314, 81.91228523446583) >>> # centroid of first labeled object >>> props[0]['centroid'] (22.72987986048314, 81.91228523446583)
透過將函式作為
extra_properties傳遞來新增自訂量測>>> from skimage import data, util >>> from skimage.measure import label, regionprops >>> import numpy as np >>> img = util.img_as_ubyte(data.coins()) > 110 >>> label_img = label(img, connectivity=img.ndim) >>> def pixelcount(regionmask): ... return np.sum(regionmask) >>> props = regionprops(label_img, extra_properties=(pixelcount,)) >>> props[0].pixelcount 7741 >>> props[1]['pixelcount'] 42
- skimage.measure.regionprops_table(label_image, intensity_image=None, properties=('label', 'bbox'), *, cache=True, separator='-', extra_properties=None, spacing=None)[原始碼]#
計算影像屬性並將它們作為與 pandas 相容的表格傳回。
該表格是一個字典,將欄名稱對應到值陣列。有關詳細資訊,請參閱下面的「備註」部分。
在 0.16 版中新增。
- 參數:
- label_image(M, N[, P]) ndarray
已標記的輸入影像。數值為 0 的標籤會被忽略。
- intensity_image(M, N[, P][, C]) ndarray,可選
與標記影像大小相同的強度(即輸入)影像,加上多通道資料的可選額外維度。通道維度(如果存在)必須是最後一個軸。預設為 None。
變更於 0.18.0 版本: 新增了提供通道額外維度的功能。
- properties字串的元組或清單,可選
將包含在結果字典中的屬性。 有關可用屬性的清單,請參閱
regionprops()。使用者應記住新增 “label” 以追蹤區域識別。- cachebool,可選
決定是否快取計算的屬性。對於快取的屬性,計算速度會快得多,但記憶體消耗會增加。
- separator字串,可選
對於未在 OBJECT_COLUMNS 中列出的非純量屬性,每個元素將會出現在自己的欄中,該元素的索引與屬性名稱之間會以這個分隔符號分隔。例如,2D 區域的慣性張量將會出現在四個欄中:
inertia_tensor-0-0、inertia_tensor-0-1、inertia_tensor-1-0和inertia_tensor-1-1(其中分隔符號為-)。物件欄是那些無法以這種方式分割的欄,因為欄的數量會根據物件而改變。例如,
image和coords。- extra_properties可迭代的呼叫物件
新增額外的屬性計算函數,這些函數不包含在 skimage 中。屬性的名稱來自函數名稱,dtype 是透過對小樣本呼叫函數來推斷的。如果額外屬性的名稱與現有屬性的名稱衝突,則額外屬性將不可見,並發出 UserWarning。屬性計算函數必須將區域遮罩作為其第一個引數。如果屬性需要強度影像,則必須接受強度影像作為第二個引數。
- spacing:浮點數元組,形狀為 (ndim,)
沿影像每個軸的像素間距。
- 傳回:
- out_dictdict
將屬性名稱對應到該屬性值陣列的字典,每個區域一個值。此字典可用作 pandas
DataFrame的輸入,以將屬性名稱對應到框架中的欄,並將區域對應到列。如果影像沒有區域,則陣列的長度將為 0,但具有正確的類型。
備註
每欄包含純量屬性、物件屬性或多維陣列中的元素。
每個區域的純量值屬性(例如「離心率」)將會以 float 或 int 陣列的形式出現,並以該屬性名稱作為鍵。
給定影像維度的固定大小的多維屬性(例如「質心」(在 3D 影像中,每個質心將會有三個元素,無論區域大小為何)),將會分割為那麼多欄,並以名稱 {property_name}{separator}{element_num} (對於 1D 屬性)、{property_name}{separator}{elem_num0}{separator}{elem_num1} (對於 2D 屬性)等等。
對於沒有固定大小的多維屬性(例如「影像」(區域的影像大小會根據區域大小而異)),將會使用物件陣列,並以對應的屬性名稱作為鍵。
範例
>>> from skimage import data, util, measure >>> image = data.coins() >>> label_image = measure.label(image > 110, connectivity=image.ndim) >>> props = measure.regionprops_table(label_image, image, ... properties=['label', 'inertia_tensor', ... 'inertia_tensor_eigvals']) >>> props {'label': array([ 1, 2, ...]), ... 'inertia_tensor-0-0': array([ 4.012...e+03, 8.51..., ...]), ... ..., 'inertia_tensor_eigvals-1': array([ 2.67...e+02, 2.83..., ...])}
如果安裝了 pandas,則產生的字典可以直接傳遞給 pandas,以獲得乾淨的 DataFrame
>>> import pandas as pd >>> data = pd.DataFrame(props) >>> data.head() label inertia_tensor-0-0 ... inertia_tensor_eigvals-1 0 1 4012.909888 ... 267.065503 1 2 8.514739 ... 2.834806 2 3 0.666667 ... 0.000000 3 4 0.000000 ... 0.000000 4 5 0.222222 ... 0.111111
[5 列 × 7 欄]
如果我們要測量未作為內建模組屬性的功能,我們可以定義自訂函式,並將它們作為
extra_properties傳遞。例如,我們可以建立一個自訂函式來測量區域中的強度四分位數>>> from skimage import data, util, measure >>> import numpy as np >>> def quartiles(regionmask, intensity): ... return np.percentile(intensity[regionmask], q=(25, 50, 75)) >>> >>> image = data.coins() >>> label_image = measure.label(image > 110, connectivity=image.ndim) >>> props = measure.regionprops_table(label_image, intensity_image=image, ... properties=('label',), ... extra_properties=(quartiles,)) >>> import pandas as pd >>> pd.DataFrame(props).head() label quartiles-0 quartiles-1 quartiles-2 0 1 117.00 123.0 130.0 1 2 111.25 112.0 114.0 2 3 111.00 111.0 111.0 3 4 111.00 111.5 112.5 4 5 112.50 113.0 114.0
- skimage.measure.shannon_entropy(image, base=2)[原始碼]#
計算影像的香農熵。
香農熵定義為 S = -sum(pk * log(pk)),其中 pk 是值為 k 的像素的頻率/機率。
- 參數:
- image(M, N) ndarray
灰階輸入影像。
- basefloat,可選
要使用的對數底數。
- 傳回:
- entropyfloat
備註
傳回的值以位元或香農 (Sh) (對於 base=2)、自然單位 (nat) (對於 base=np.e)和哈特利 (Hart) (對於 base=10)測量。
參考文獻
範例
>>> from skimage import data >>> from skimage.measure import shannon_entropy >>> shannon_entropy(data.camera()) 7.231695011055706
- skimage.measure.subdivide_polygon(coords, degree=2, preserve_ends=False)[原始碼]#
使用 B 樣條對多邊形曲線進行細分。
請注意,產生的曲線始終位於原始多邊形的凸包內。圓形多邊形在細分後會保持封閉。
- 參數:
- coords(K, 2) 陣列
座標陣列。
- degree{1, 2, 3, 4, 5, 6, 7},可選
B 雲線的次數。預設值為 2。
- preserve_endsbool,可選
保留非圓形多邊形的第一個和最後一個座標。預設值為 False。
- 傳回:
- coords(L, 2) 陣列
細分的座標陣列。
參考文獻
- class skimage.measure.CircleModel[原始碼]#
基礎:
BaseModel2D 圓的總最小二乘估計器。
圓形的功能模型為
r**2 = (x - xc)**2 + (y - yc)**2
此估算器會最小化所有點到圓形的平方距離
min{ sum((r - sqrt((x_i - xc)**2 + (y_i - yc)**2))**2) }
至少需要 3 個點才能求解參數。
- 屬性:
- params元組
依下列順序排列的圓形模型參數
xc、yc、r。
備註
估算是使用 [1] 中給出的球面估算的 2D 版本進行的。
參考文獻
[1]Jekel, Charles F.。透過反向氣泡膨脹獲得 pvc 塗層聚酯的非線性正交異性材料模型。論文(MEng),Stellenbosch 大學,2016 年。附錄 A,第 83-87 頁。 https://hdl.handle.net/10019.1/98627
範例
>>> t = np.linspace(0, 2 * np.pi, 25) >>> xy = CircleModel().predict_xy(t, params=(2, 3, 4)) >>> model = CircleModel() >>> model.estimate(xy) True >>> tuple(np.round(model.params, 5)) (2.0, 3.0, 4.0) >>> res = model.residuals(xy) >>> np.abs(np.round(res, 9)) array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
- estimate(data)[原始碼]#
使用總最小平方法從資料估算圓形模型。
- 參數:
- data(N, 2) 陣列
分別具有
(x, y)座標的 N 個點。
- 傳回:
- successbool
如果模型估算成功,則為 True。
- class skimage.measure.EllipseModel[原始碼]#
基礎:
BaseModel2D 橢圓的總最小二乘估計器。
橢圓的函數模型為
xt = xc + a*cos(theta)*cos(t) - b*sin(theta)*sin(t) yt = yc + a*sin(theta)*cos(t) + b*cos(theta)*sin(t) d = sqrt((x - xt)**2 + (y - yt)**2)
其中
(xt, yt)是橢圓上最接近(x, y)的點。因此,d 是點到橢圓的最短距離。估計器基於最小平方最小化。直接計算最佳解,無需迭代。這產生一個簡單、穩定且穩健的擬合方法。
params屬性包含以下順序的參數xc, yc, a, b, theta
- 屬性:
- params元組
橢圓模型參數,依以下順序排列:
xc、yc、a、b、theta。
範例
>>> xy = EllipseModel().predict_xy(np.linspace(0, 2 * np.pi, 25), ... params=(10, 15, 8, 4, np.deg2rad(30))) >>> ellipse = EllipseModel() >>> ellipse.estimate(xy) True >>> np.round(ellipse.params, 2) array([10. , 15. , 8. , 4. , 0.52]) >>> np.round(abs(ellipse.residuals(xy)), 5) array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
- estimate(data)[原始碼]#
使用總最小平方從數據估計橢圓模型。
- 參數:
- data(N, 2) 陣列
分別具有
(x, y)座標的 N 個點。
- 傳回:
- successbool
如果模型估算成功,則為 True。
參考文獻
[1]Halir, R.; Flusser, J. “Numerically stable direct least squares fitting of ellipses”. In Proc. 6th International Conference in Central Europe on Computer Graphics and Visualization. WSCG (Vol. 98, pp. 125-132).
- class skimage.measure.LineModelND[原始碼]#
基礎:
BaseModelN 維直線的總最小二乘估計器。
與普通最小平方線估計相反,此估計器會最小化點到估計線的正交距離。
線條由一個點(原點)和一個單位向量(方向)根據以下向量方程式定義
X = origin + lambda * direction
- 屬性:
- params元組
線模型參數,依以下順序排列:
origin、direction。
範例
>>> x = np.linspace(1, 2, 25) >>> y = 1.5 * x + 3 >>> lm = LineModelND() >>> lm.estimate(np.stack([x, y], axis=-1)) True >>> tuple(np.round(lm.params, 5)) (array([1.5 , 5.25]), array([0.5547 , 0.83205])) >>> res = lm.residuals(np.stack([x, y], axis=-1)) >>> np.abs(np.round(res, 9)) array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) >>> np.round(lm.predict_y(x[:5]), 3) array([4.5 , 4.562, 4.625, 4.688, 4.75 ]) >>> np.round(lm.predict_x(y[:5]), 3) array([1. , 1.042, 1.083, 1.125, 1.167])
- estimate(data)[原始碼]#
從數據估計線模型。
這會最小化從給定的數據點到估計線的最短(正交)距離總和。
- 參數:
- data(N, dim) 陣列
N 個點,位於維度 dim >= 2 的空間中。
- 傳回:
- successbool
如果模型估算成功,則為 True。
- predict(x, axis=0, params=None)[原始碼]#
預測估計的線模型與垂直於給定軸的超平面的交點。
- 參數:
- x(n, 1) 陣列
沿著軸的坐標。
- axis整數
與相交線的超平面垂直的軸。
- params(2,) 陣列,可選
可選的自訂參數集,格式為 (
origin,direction)。
- 傳回:
- data(n, m) 陣列
預測的坐標。
- 引發:
- ValueError
如果線平行於給定的軸。
- predict_x(y, params=None)[原始碼]#
使用估計的模型預測 2D 線的 x 坐標。
別名為
predict(y, axis=1)[:, 0]
- 參數:
- y陣列
y 坐標。
- params(2,) 陣列,可選
可選的自訂參數集,格式為 (
origin,direction)。
- 傳回:
- x陣列
預測的 x 坐標。